
Highlights
Pinterest: Shallow Mirror
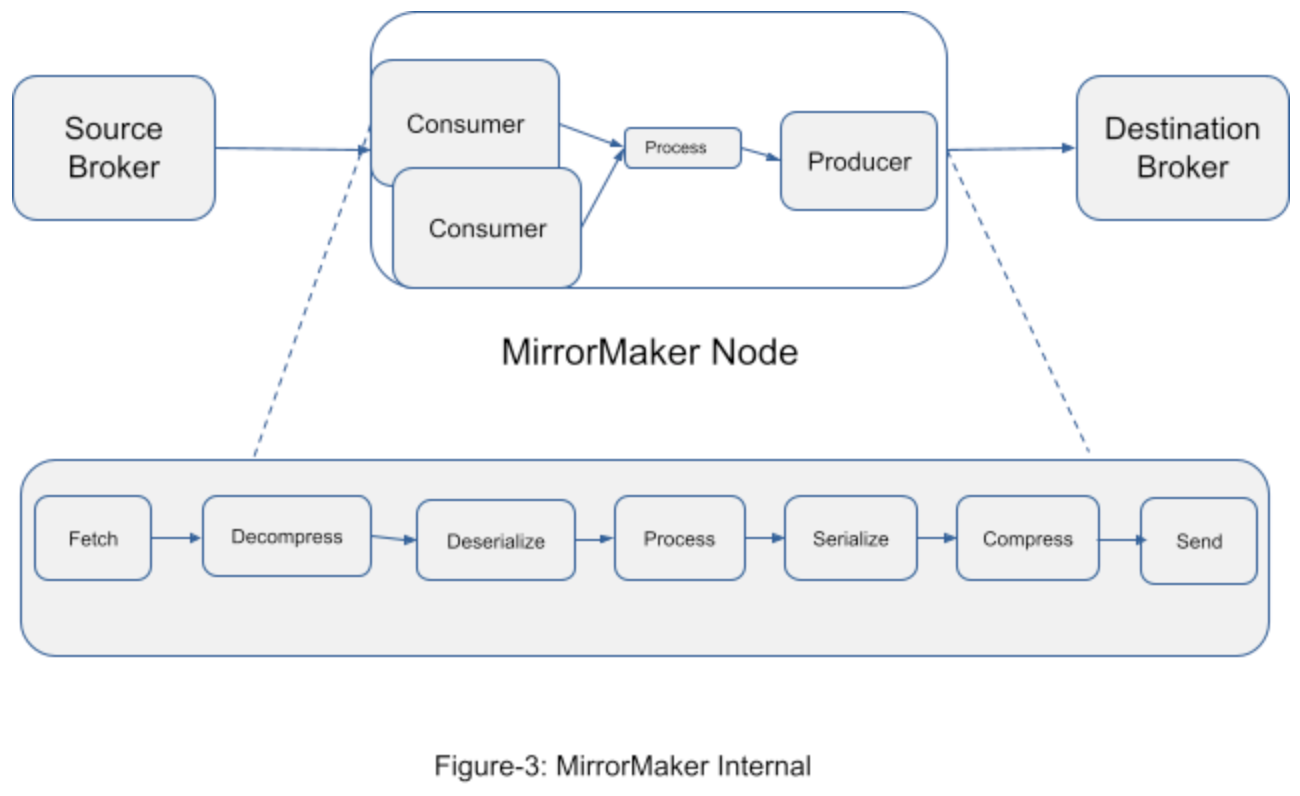
Kafka MirrorMaker is a tool to replicate Kafka clusters across different regions. Data from different Source Brokers is transferred to MirrorMaker which then sends this data to Destination Brokers in other regions. Pinterest started experiencing scalability issues at some point.
Monitoring showed some CPU and memory spikes. During the investigation, it became apparent that most of the CPU time was spent on message decompression and recompression. Memory consumption was often 2-10 times bigger than the actual data being sent. This picture represents Kafka MirrorMaker internals.
The reason for message decompressing and deserializing is the ability of plugins to transform the message. However, Pinterest doesn’t use this functionality. MirrorMaker is used only for replication purposes.
The initial thought to fix this is to send compressed messages directly to the destination broker. It turned out that messages are packaged based on topics and partitions, so there is a need to repackage. Luckily, while messages inside the batches are compressed, the package headers are not, so it’s possible to extract messages without decompression. The Pinterest team created Shallow Mirror functionality for Kafka MirrorMaker that allows regrouping batches without decompressing the message inside the batch.
The Pinterest team deployed their version of MirrorMaker and observed a significant reduction in CPU and memory consumption. After battle testing, several issues were discovered. Passing just pointers to bytes between sender and receiver to avoid deep copy didn’t work because the batch contained an offset that is not relevant after the batch regroup.
Another issue was consumers receiving extra messages. Turned out that batches contained non-relevant messages, so the solution was cropping the batch. Next issue: small batches need more network due to specifics of TCP connection. Turned out that MemoryRecord better to contain several batches.
Finally, MirrorMaker got so fast that another bottleneck was discovered. Broker reconstructed batches to translate messages to different formats. The Pinterest team also fixed that issue.
The proposal to add Shallow Mirror functionality awaits approval for the merge to upstream Kafka.
PayPal: Low latency file transfers with DropZone
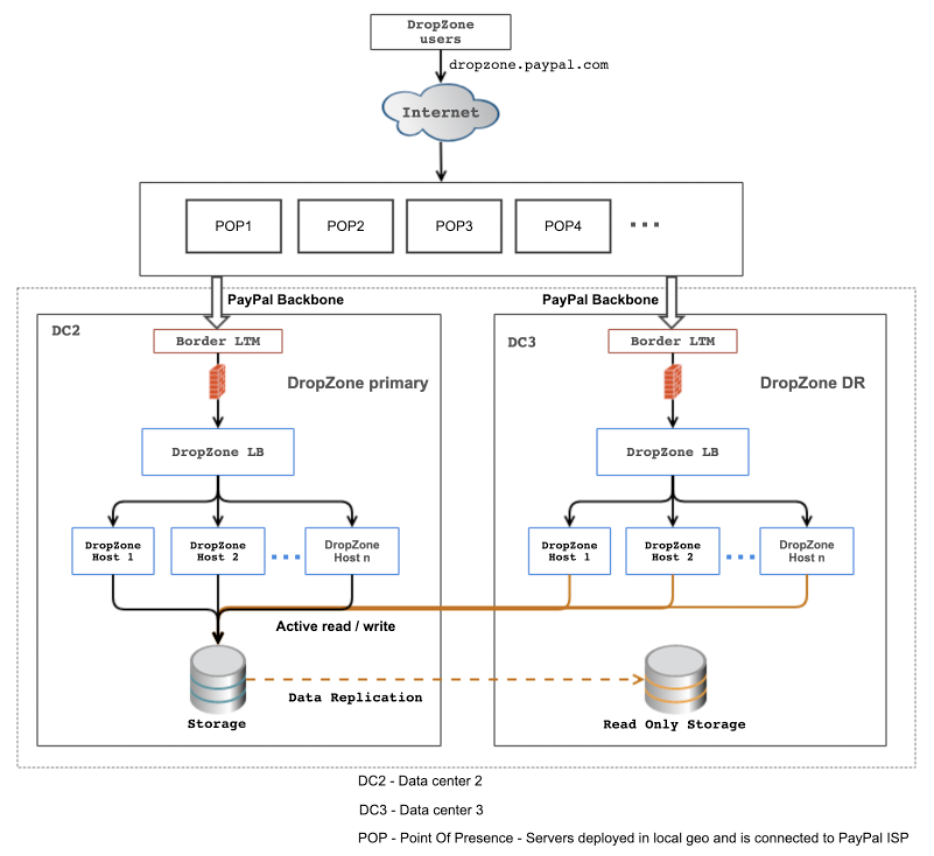
PayPal has a secure file transfer platform called DropZone. The team’s objective was to improve user experience with low latency file uploads using existing edge infrastructure. Internet speed is often measured with bandwidth and latency. Bandwidth represents the data transferred over a period of time, for example, 1Mbps. Network latency is the time taken for a packet to travel from the source of origin to its destination. Round trip time (RTT) measures the time for a packet to come back to the origin source. It’s not always double the time because the return route can be different. Processing time also adds to RTT. The speed of light in optic fiber is around 200,000 km/s or 200 km/ms.
“Transferring a single TCP packet from Sydney to Los Angeles takes at least 125ms using optical fibre. With a max TCP packet size of 64KB, the number of round trips required to transfer a 1GB file would be 15625; in other words, it would take at least 33 minutes to transfer a 1GB file.”
To make things worse, last-mile latency significantly decreases overall speed due to numerous hops, routing, congestion, etc. While we can’t overcome the speed of light, we can reduce last-mile latency.
If a client wants to upload a file to a remote server, that means last-mile latency is going to be a factor on both sides of the transfer. PayPal has a distributed across the globe server infrastructure. By routing requests to the nearest to the client Edge server, PayPal leverages existing POPs and Edge infrastructure while reducing the last mile latency. DNS resolves to different IPs worldwide pointing to PayPal’s nearest Edge servers.
This architecture not only significantly increased the file uploads speed but also improved disaster recovery as it mitigates a single point of failure.
Everything you need to know about DynamoDB Partitions
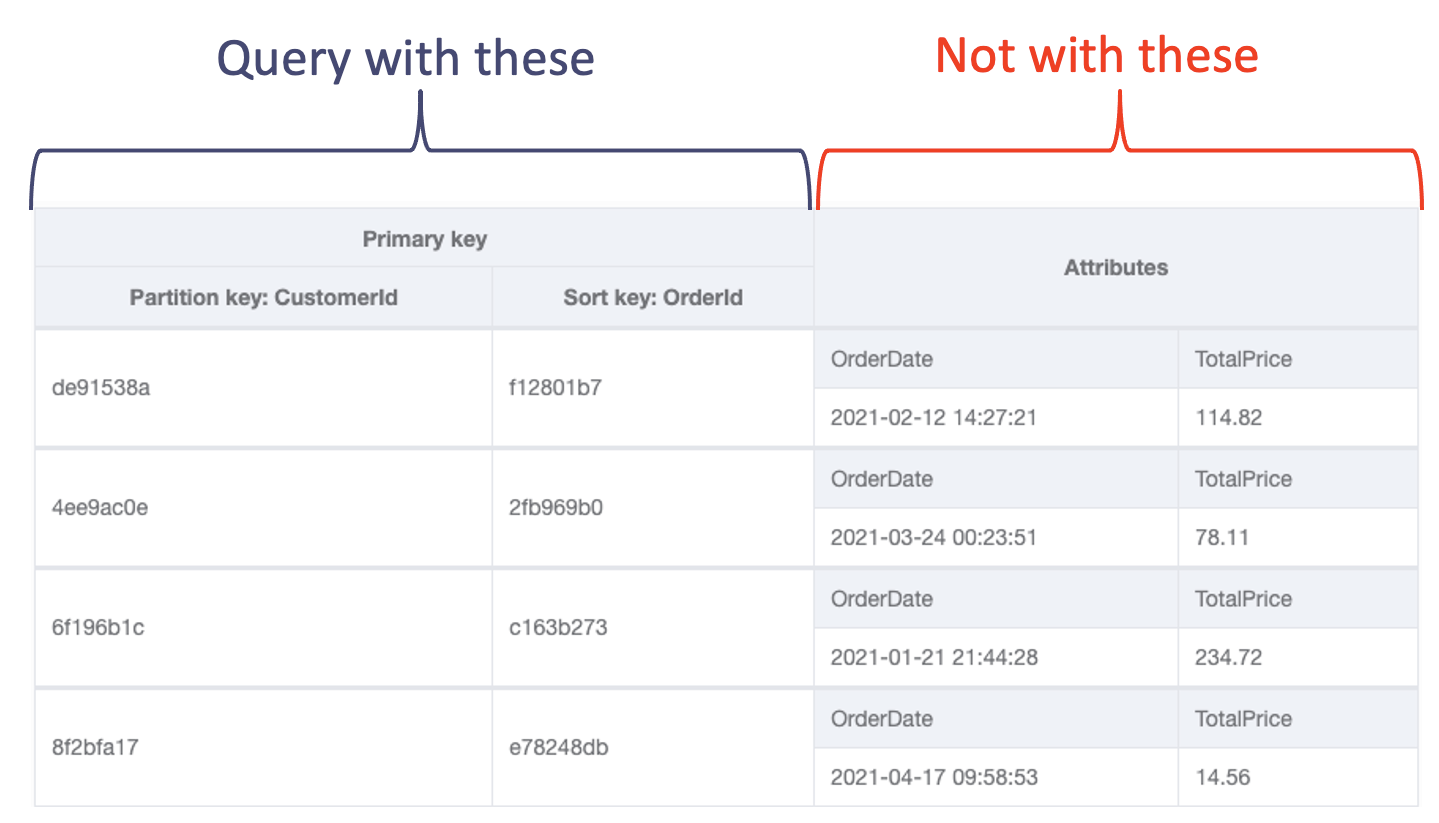
DynamoDB may seem like a large black box database but in reality, it’s a distributed key-value storage. Understanding partitions is the key to understanding DynamoDB. Each record should contain a primary key. It can be a simple key or a composite key. The simple key is also called the partition key. Composite key in addition to partition key should contain a sort key. In this case, the combination of these two keys makes the record unique.
When you request DynamoDB, it hits the router first. The router gets the metadata from the request, extracts the partition key, and applies a hash function to it. Thanks to the resulting hash value, the router can understand which DB partition is responsible for the request. The time complexity of finding the appropriate node is O(1). Each partition is about 10GB. Amazon adds partitions automatically as your table grows. With this constant time, Amazon can scale DynamoDB horizontally to thousands of partitions.
The fact that all requests pass through a router, distinguishes DynamoDB from other NoSQL databases like Cassandra, where clients should be topology-aware. DynamoDB client doesn’t have to maintain cluster metadata.
Understanding this partition aspect helps to understand DynamoDB constraints. Scan is an expensive operation because it searches database across partitions as a partition key is not provided. Query reads a range of records as partition key is specified. Single record operations are straightforward.
Design your table to make efficient queries. For example, if you need to make geo-lookups, break down a dataset into countries, states, cities, etc. A narrow initial search then provides an in-memory filter.
Partitions explain the absence of JOINs, as data would be joined across different partitions, and needs a separate node to perform the join operation. You would probably need to denormalize data to work around the absence of JOIN.
Building Hulu’s Living Room Experience with Amazon Alexa
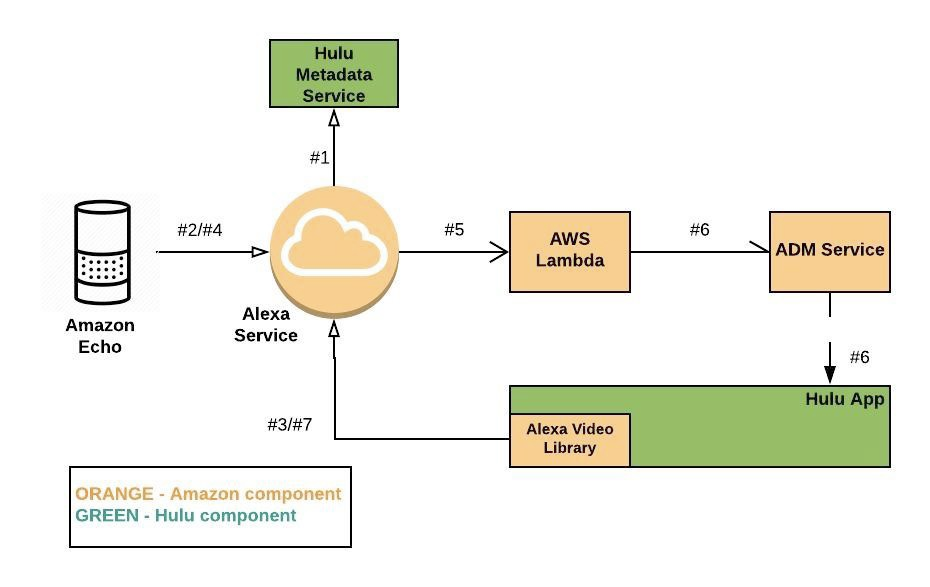
Hulu app for Fire TV allows voice commands via Alexa devices like Echo or Dot. Users can watch a TV show, channel, and control playback with voice commands like “Alexa, watch The Handmaid’s Tale.”
This command system is built with Video Skill API in the Alexa Skills Kit. Hulu metadata service exports catalog to Amazon Alexa service. This Alexa service converts voice commands into Alexa directives. Lambda functions convert these directives to Hulu-specific actions. Amazon ADM service sends push notifications to the Hulu Fire TV app. This app executes directives received from ADM on the TV device. Alexa Video Library registers the Hulu app with the Alexa service and activates Hulu video skill on app startup.
Data Science
Optimizing payments with machine learning - how to pick the best time to charge the customer’s credit card? “We took an 8 day window and divided it into one-hour chunks, resulting in a total of 192 time chunks. We used our models to find the highest ranking time chunk to attempt the renewal.”
Our journey to building a managed orchestration system at Bloomberg
How Airbnb Achieved Metric Consistency at Scale - “When Brian, our CEO, would ask simple questions like which city had the most bookings in the previous week, Data Science and Finance would sometimes provide diverging answers using slightly different tables, metric definitions, and business logic.” A journey of Airbnb data paltform - Minerva.
Tutorials
Optimizing serverless development with samconfig - Infrastructure as Code for AWS Lambda
Product News
turbolift by Skyscanner - a simple tool to help apply changes across many GitHub repositories simultaneously
How we made DISTINCT queries up to 8000x faster on PostgreSQL - it turns out that PostgreSQL currently lacks the ability to efficiently pull a list of unique values from an ordered index. New version of TimescaleDB supports Skip Scan, including Postges tables.
Auth0 Actions Is Now Generally Available - run custom code triggered by user actions
pprof++: A Go Profiler with Hardware Performance Monitoring - Uber created a better Go profiler
System Design
How does Airbnb track and measure growth marketing? - Airbnb decided not to use Google’s UTM tracking, designed their own tracking system instead.
The Architecture of Uber’s API gateway - Uber team has implemented an in-house API gateway in Go. It’s cool, here is what it can do.
DNS infrastructure at Hulu - this article starts with “For companies running their own datacenter…”. And then lots of fun configuring DNS.
The Technology Behind KFC’s Finger Lickin’ Good Success - KFC share their AWS design patterns
Boosting Dropbox upload speed and improving Windows’ TCP stack - Dropbox engineers debug uncharted territory - Windows networking system
Docker Hub Incident Reviews – April 3rd and 15th 2021 - tldr; 1) load balancer was autoscaled for bandwidth but it was scaled down over the weekend to lower CPU instance; 2) service discovery was updated in the wrong order - no valid backends.
The Internals of PostgreSQL - an entire free online book on PostgreSQL internals.
Culture
That Salesforce outage: Global DNS downfall started by one engineer trying a quick fix - it’s always DNS but now with race conditions. Salesforce kind of blame a DevOps engineer while deny that they blame but “We have taken action with that particular employee”. This is how not to post mortem.