
Highlights
DoorDash: Building Faster Indexing with Apache Kafka and Elasticsearch
The DoorDash team faced an issue of a very long time for updating the search index. They’ve built a search system relying on open source technologies. It uses Kafka as a message queue and for data storage, Flink for data transformation, and sending data to Elasticsearch. A reliable indexing system would ensure that changes in stores and items are reflected in the search index in real-time.
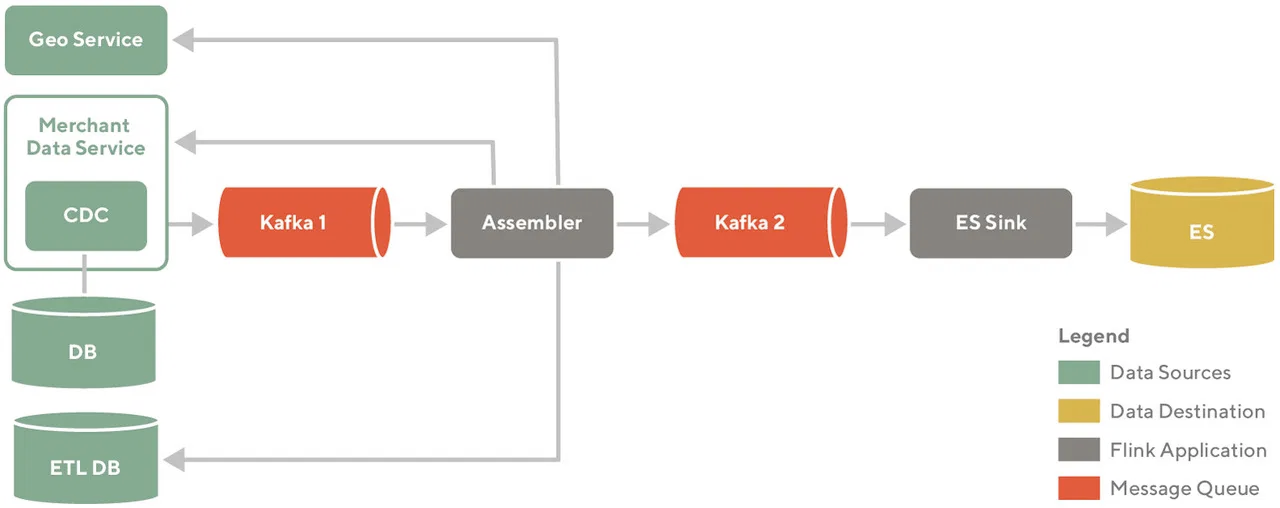
The system can be divided into four big components.
Data sources are Postgres database or Snowflake data warehouse. They are the source of truth for data.
Data destination represents Elasticsearch, a datastore that is optimized for search.
Flink applications are Assemblers for transforming data and Sinks for sending data to the destination storage. Assemblers are responsible for assembling all the data required in an Elasticsearch document. Sinks are responsible for shaping the documents as per the schema and writing the data to the targeted Elasticsearch cluster.
The message queue is Kafka with log compacted and preserved indefinitely topics.
The resulting system represents an end-to-end data pipeline.
Merchant data gets updated constantly, for example, the restaurant menu is updated. The DoorDash team explored change data capture (CDC) technology for Aurora/Postgres using Debezium connector, a Red Hat-developed open source project for capturing row-level changes. Performance tests showed that this strategy had too much overhead and was not performant.
It was decided to use Application Level CDC. As the application receives an update request, it propagates change events through Kafka in addition to saving the change to the underlying datastore.
In some cases, multiple instances of the application can make changes to the same item at the same time. To ensure consistency, only changed entity IDs are sent into the Kafka events. Assembler app calls REST APIs on the application to gather other information about entities that are present in Kafka events. It then creates an event and pushes it to Kafka for the Sink app to consume.
Assembler prevents calling REST APIs for the same entity multiple times within a specified amount of time. It also aggregates events to call REST endpoints in bulk.
For the ETL case, there is a variant of the Application Level CDC for the ETL sources. A custom Flink source function periodically streams all the rows from an ETL table to Kafka in batches, where the batch size is chosen to ensure that the downstream systems do not get overwhelmed.
The Sink consumer reads the hydrated messages, transforms the messages according to the specific index schema, and sends them to their appropriate index. The Sink process utilizes Flink Elasticsearch Connector to write JSON documents to Elasticsearch. Out of the box, it has rate limiting and throttling capabilities, essential for protecting Elasticsearch clusters.
Sometimes there is a need to backfill the index to a add new property. In this case, all the document IDs which needed to be indexed in Elasticsearch should be added to Kafka. For bootstrapping, the source function described in the ETL section streams all the rows from these bootstrap tables to Kafka.
Some documents in Elasticsearch might have stale data. In this case, there is a need to force a reindex of any documents in question. To do this, send a message with the ID of the entity to be indexed into the topic from which the online assembler consumes data.
Each message has a unique tag that provides a detailed trace of the document as it passes through the various stages of the indexing flow. It provides debugging information.
As a result, the search index is always up to date. A backfilling time was reduced from one week to 6,5 hours.
GitHub: Adding support for cross-cluster associations to Rails 7
GitHub runs on their fork of Rails. This monolith application works with 15 primary and 15 replica MySQL databases. The partitioning is functional. Unlike horizontal sharding, functional partitioning means that each database has its schema and store a different kind of data.
Such partitioning has some tricky joining as one database cluster can’t join data with another. This means that such joins should be done by the application by performing two different SQL queries and then joining the results. Such work for “manual” joins and writing SQL queries is error-prone.
GitHub team wanted to contribute back to the Rails community, so they decided to solve this problem and merge the solution to the upstream Rails. The implementation itself is fairly simple. Each ORM association gets a new option disable_joins. If set to true, ORM generates two SQL queries instead of a join query.
The functionality was implemented around two years ago. The GitHub team wanted to make it stable and successfully run it in production before merging it to Rails.
This feature should be used with caution. Tables should have proper indexes. As join is now made in-memory by an application, performing it on large tables with hundreds of thousands of records should be avoided.
The Forrester Wave™: Cognitive Search, Q3 2021
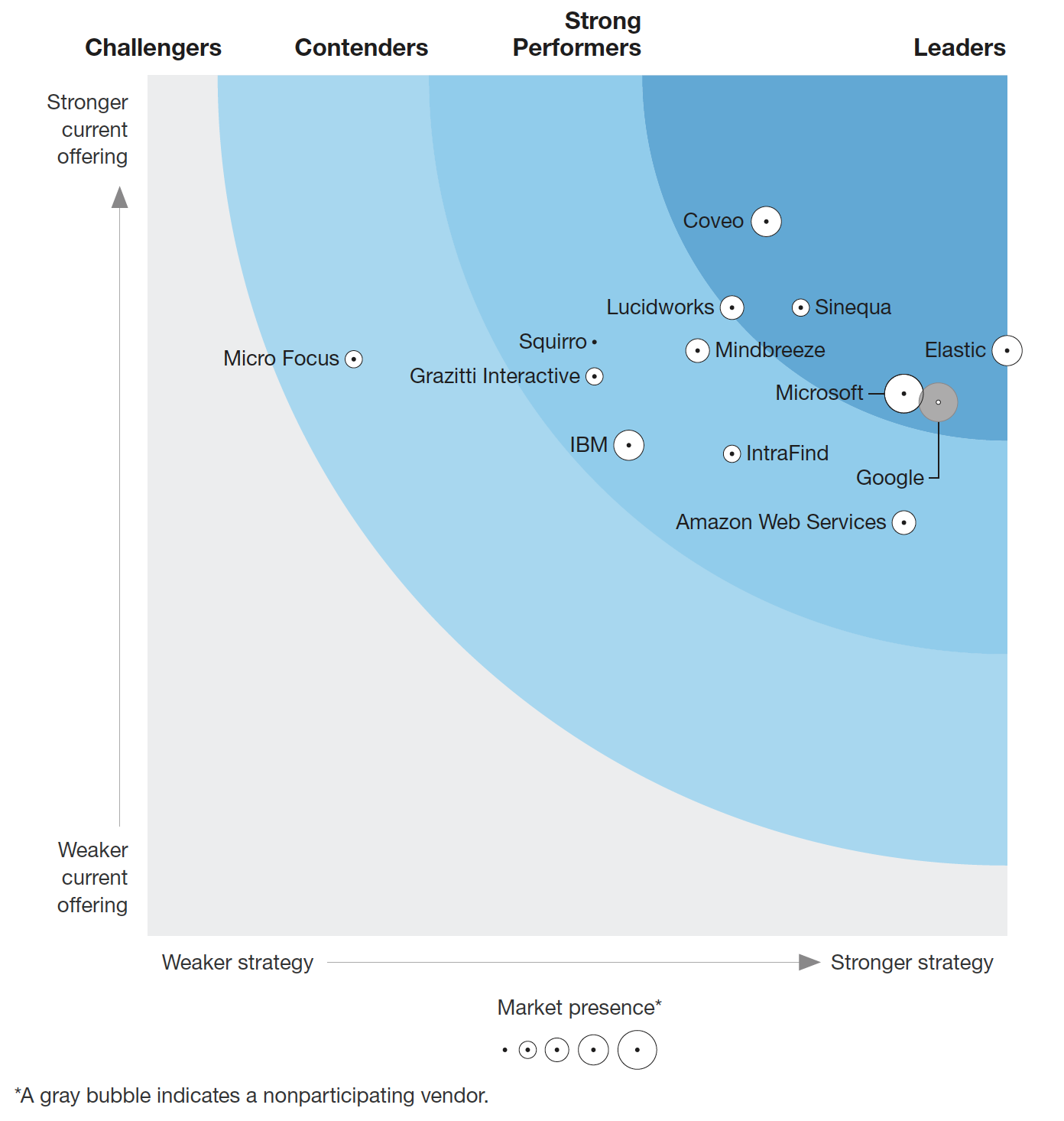
Forrester has published their Cognitive Search report. Key takeaways:
- Elastic is better than ever with enterprises features. Elastic is the company behind the Elastic Stack — which includes Elasticsearch, Kibana, Beats, and Logstash. Customers can use Enterprise Search for workplace search, site search, and embedded application search.
- Coveo covers all the bases with 360-degree search experiences. Notable for digital commerce is Coveo’s use of AI, specifically to understand the nuances of shoppers’ intent, leading to a better experience and more conversions. The company has integrations with other platforms, including Salesforce, Sitecore, and ServiceNow.
- Sinequa supports the most human languages among all evaluated vendors, so it is also particularly well suited for global enterprises and organizations.
The complimentary copy of the report can be downloaded from the Elastic website.
Uber: Customer Support Automation Platform
As Uber scale globally with various products (Rides, Eats, Freight, etc.), they faced challenges and inefficiencies around customer service interactions. Their previous solution, Policy Engine, did not scale, since it required an engineer to write custom logic for each non-happy path scenario, which had regional variance and edge cases.
Uber team considered Drools, an open-source business rules management system that could be used to execute a chain of rules. However, Drools is Java-based, which would require the server-side execution framework’s implementation to be written in Java instead of Golang, which is preferred at Uber. It was decided to build an in-house solution.
The back-end service is written in Glue (Uber’s internal MVCS framework). Persistence is done on Percona DB (MySQL) clusters. Redis is used as a cache. The front-end leverages Uber’s React framework, Fusion.JS. Configuration-based data aggregation (think “GraphQL” for Go) was created for the “data aggregation” framework. Uber team developed drag-and-drop features to author workflow versions by adopting Uber’s flowchart library react-digraph.
Since the data model for flows was expected to be highly relational, requiring multiple indexes, cell mutability, and <100k rows, it was decided to use MySQL. GORM is used to read and write MySQL tables.
GraphQL was considered for data retrieval, however, due to complex schema definition semantics and performance concerns, it was rejected. Currently, self-serve hydrations support typed RPCs (e.g. Apache Thrift, Protobuf) as well as generic REST APIs.
In evaluating which DSL to use for expression evaluation, the Uber team went back and forth between an existing DSL/JSONPath hybrid and a plain JavaScript. It was decided to use JS to avoid having to define/maintain custom DSL. The V8 engine is leveraged to run the JS snippets in the back-end.
Culture
The Secret of Growing Teams - spoiler alert: “Clarity is being free from ambiguity”.
Saying The Quiet Part Out Loud — Authoring the Zendesk Engineering Job Architecture
Dropbox Engineering Career Framework - Dropbox has opened its career framework to the world. It describes different levels for various positions, like Software Engineer, Engineering Manager, Quality Assurance Engineer, Reliability Engineer, and more.
Internationalizing and Localizing Your App, Part 1: Understanding Different Cultures - What color would you paint an error message? In western culture, it’s probably red. However, in Chinese culture, red is associated with positives like happiness and prosperity. Western financial markets use green to signify increase and red to denote decrease, whereas Eastern financial markets will do the exact opposite: 📈. Stylistically, we can’t even assume that our colors and themes make sense.
Tutorials
Generating JSON Directly from Postgres
Product News
Our Roadmap for QUIC and HTTP/3 Support in NGINX - “The changes to the NGINX core are relatively small (~3000 lines of code). The larger task is merging the transport protocol code (~27,000 lines of code). Based on our experience merging our HTTP/2 implementation into NGINX, we expect this work to take several months.”
Articles and Blogs
DocumentDB, MongoDB and the Real-World Effects of Compatibility