
Highlights
Cloudflare: The benefits of serving stale DNS entries when using Consul

Cloudflare faced an issue with long latencies for DNS responses in certain parts of the world. In addition DNS over TLS is also a factor. They use Unbound as a DNS resolver. For a better failover, they set 30 seconds TTL for such responses.
There are two options to solve this problem. The first is prefetching. This means that on each request TTL is checked. If it’s less than 10%, then a background task prefetches this record for the next request. This approach doesn’t work well for short TTLs or rare requests.
Another option is stale cache. In this case, an expired record is returned to the client while a background job tries to get the updated result for the future request. This improves latency results significantly.
Cloudflare tried stale cache option back in 2017 but Unbound support for this feature was limited at the time. New versions of Unbound provide more options to configure, so Cloudflare team explores different parameters in this article to make sure this time it satisfies their need. This time all tests cases worked perfectly, so Cloudflare rolled this out to production. Resulting graphs with dramatic changes are provided in the article.
Capital One: Moving to DynamoDB to Increase Application Resiliency
Capital One faced a resilience issue between their east and west AWS regions PostgreSQL databases. Failover took several minutes. Their team leveraged managed AWS solutions, so their primary options were Aurora Global Database, Aurora Multi Master, DynamoDB.
Aurora Global Database was almost perfect solution with one minute failover but at the time it only supported MySQL (since their decision was made, it also supports PostgreSQL). Aurora Multi Master supports multiple primary database but only within a single region. DynamoDB is multi-region active-active, requires no failover but it’s a NoSQL which means a lot of changes in the application.
The decision was made in favor of DynamoDB as it’s a single active-active multi-region solution. The replication time in most cases is around 1 second. Migrating application turned out not as hard as expected with a few interesting findings, like absence of NULL or blank values, and no datatype for date and time. They converted datetime values into ISO UTC. For NULL values they created a NULL structure.
As a first step of migration, application read/write were directed to both PostgreSQL and DynamoDB but results were only returned from PostgreSQL. After several weeks with no errors in production they turned off PostgreSQL.
Varo: Event-Driven Architecture and the Outbox Pattern
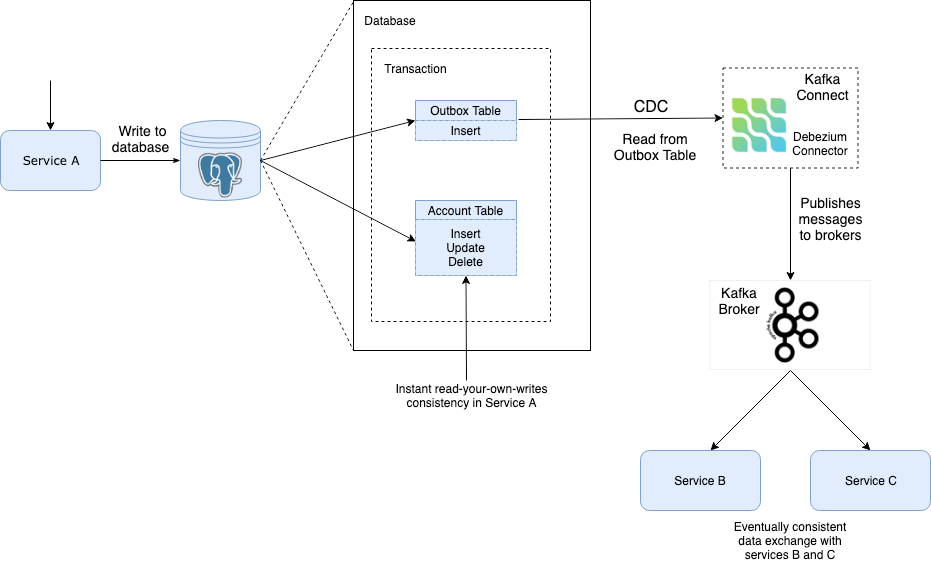
Let’s imagine an event based architecture where database write and Kafka event should happen as one transaction. In case of DB write fail, Kafka message will be sent anyway. In case of Kafka fail, data was persisted in the DB but further pipeline with Kafka would not work.We should make both components interdependent. If we write to Kafka first, we lose “read your own write” ability.
Here comes an Outbox pattern. We write our data to DB, and we also write an event-like record to a special outbox table in the DB in one transaction. A separate process is responsible of getting updates from the outbox table and delivering them to Kafka.
Frontend at Lyft: An Overview
Besides the actual app, Lyft frontend team is also responsible for other internal and external frontend related parts, for example web portal, affilliate sites, Hertz integration, etc. Historically, one monolith Angular application worked with numerous backend microservices. Paradigm then shifted to one frontend application for one backend service, although ratio is not always 1:1. Lyft migrated from Angular to React, from Express to Next. They also heavily rely on Typescript.
Frontend engineers are vertically oriented, meaning that there is no Frontend department. Each team that develops a certain service has one or several frontend engineers. Consequently, such engineers request a code review from their colleagues at other teams.
IBM: Compare deep learning frameworks
This article is an introduction into deep learning. It explains strengths and use cases for different frameworks while also telling a story of their development. Main focus is on TensorFlow, Keras, and PyTorch. It also explains that Keras isn’t really a framework, rather a library API for other backend frameworks that do the heavylifting, mostly shifting its support to TensorFlow now.
System Design
How I built a monitoring system for my avocado plant with Arduino and Grafana Cloud
How OLX Europe Fights Millions of Bots with AWS
Groupon Push Marketing — How we send almost half a billion notifications a day
Lessons Learned from Scaling Up Cloudflare’s Anomaly Detection Platform
Capturing Every Change From Shopify’s Sharded Monolith
Pinterest Flink Deployment Framework
Software Architecture
Micro Frontends: from Fragments to Renderers (Part 1)
Culture
Building a Healthy On-Call Culture
Products
ConsoleMe: A Central Control Plane for AWS Permissions and Access
Go Developer Survey 2020 Results
Redis 6.2—the “Community Edition”—Is Now Available
ARMs Race: Ampere Altra takes on the AWS Graviton2
Grafana Loki 2.2 released: Multi-line logs, crash resiliency, and performance improvements