
Highlights
Slack: Migrating Millions of Concurrent Websockets to Envoy
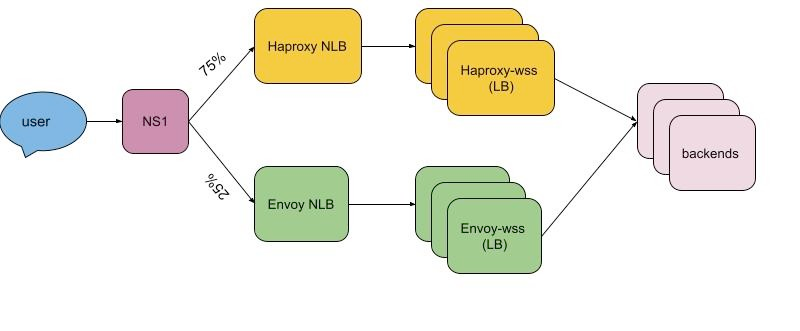
Slack makes an extensive use of websocket technology for their messaging service. Historically, they used HAProxy as a load balance, however, they faced an issue with dynamic updates of a list of endpoints. They could also change config and restart a load balancer which is tricky as it has to maintain existing websocket connections.
They’ve decided to switch to Envoy proxy as it allows dynamic change of the configuration. Also it’s able to hot-restart without dropping connections. The article describes migration and testing process.
Interesting findings from the migration. It’s hard to differentiate between useful config and technical debt. It’s hard to figure out why some rule is in place. In some cases they were even forced to replicate mistakes in HAProxy configuration to Envoy because existing system relies on them.
GitHub: How we found and fixed a rare race condition in our session handling
GitHub received two reports from users over a short period of time that they were logged in under another user account. It looked like some recent change caused this bug so the first suspect was the load balancer config update, however, that wasn’t the case.
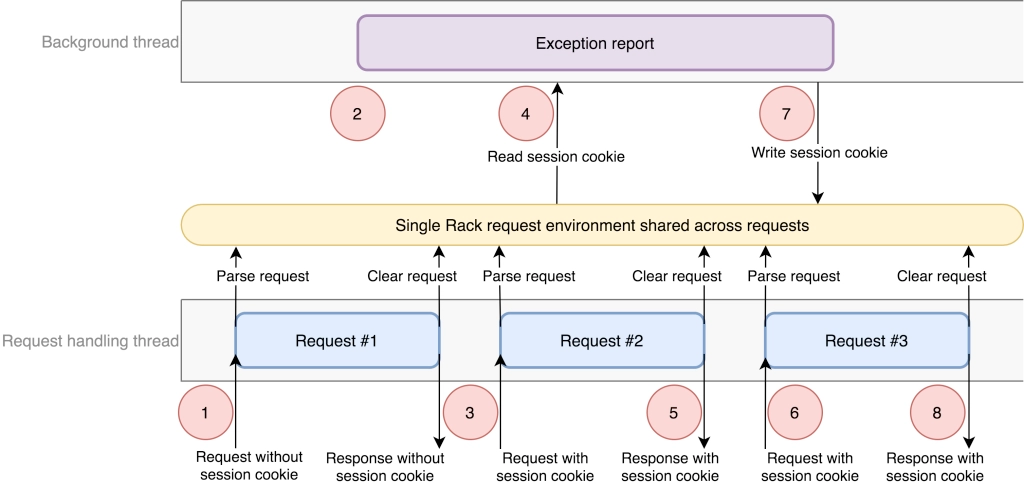
The next suspect is an application. It turned out that incorrect sessions happened on the same machine within the same process. Tech stack: Ruby on Rails with Unicorn Rack web server. Further investigation showed that HTTP body was correct but cookies sent to the client were cookies from another user that was recently handled within the same process.
This was caused by a recent change in the architecture: some user related logic was moved to a background thread, the state of which was checked per some interval. Rack server created a single Ruby Hash object that was reused between requests, which led to a race condition. It would only happen in a very rare occurrence of several conditions at the same time.
GitHub team removed the thread, created patch to Unicorn, examined logs to find affected users, revoked all user session.
How PayPal moves secure and encrypted data across security zones
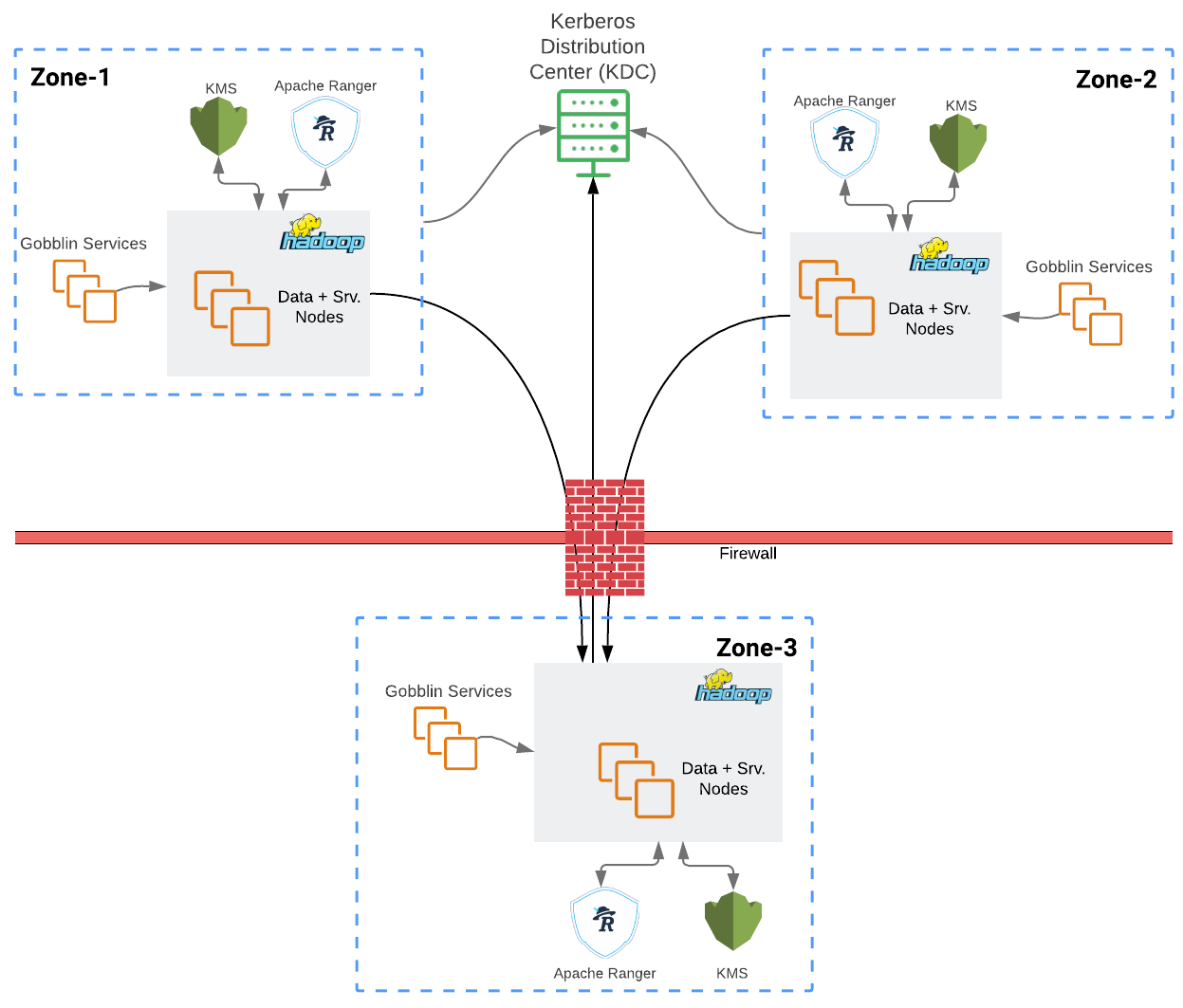
As a global payment company, PayPal works with data across different regions and datacenters with high InfoSec requirements. Some of the key principles: only a higher security zone can initiate a connection to a lower security zone. Data at rest must be encrypted. Previously PayPal used in-house developed secure-FTP solution for large files and Kafka for real-time messages.
New solution is based on Hadoop and Kerberos. Hadoop is able to work with secure sockets over TLS 1.2. Authorization relies on a single Kerberos KDC (key distribution center). Data is transparently encrypted and decrypted with Hadoop TDE (Transparent Data Encryption) .
OLX: Cassandra Compaction Trade-Offs
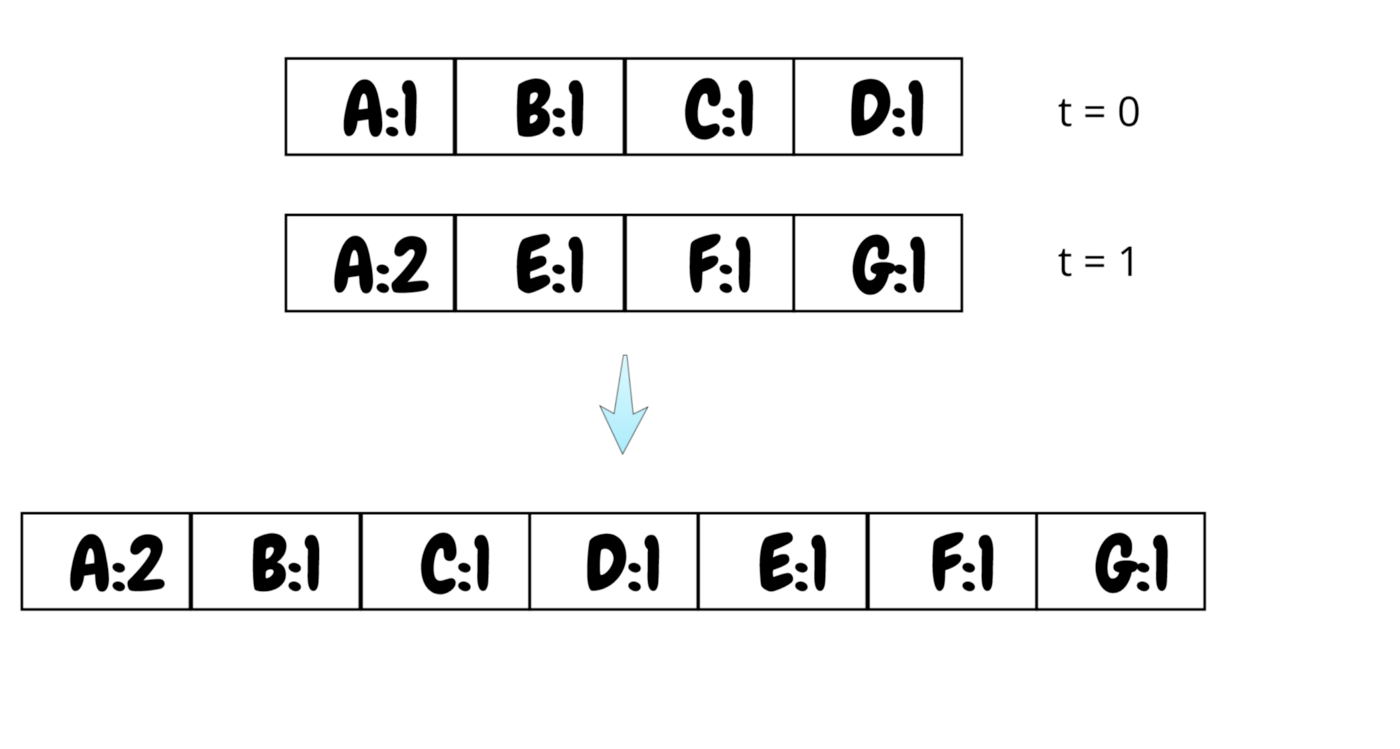
Cassandra is an obvious choice for storing messages that users send to each other as such data is easily shardable per user ID. First, Cassandra appends data in memory and then writes it to SSTable using LSM data structure. Article shortly describes this concept.
Furthermore this blog post explores compaction problem and amplification factor, particularly, tradeoffs of different Cassandra compaction strategies. Initially, OLX used Time Window Compaction Strategy which lead to CPU spikes and huge read amplification factor (raf). This can be diagnosed with nodetool, usage example is provided in the article.
As the goal was to lower read latencies, OLX changed their Cassandra strategy to Leveled Compaction Strategy which was further proved as a good decision based on the measurements and graphs provided in the article.
Uber: Journey Toward Better Data Culture From First Principles

Uber heavily relies on big data and data science. As a company that works extensively with data, they faced issues like: data duplication, inconsistencies, lack of ownership, etc. This led to developing a culture framework for working with data.
Key takeaways. Data should be treated as code: proper documentation, review process, deprecation, etc. Each data artifact should have a clear owner and purpose. Data should have SLA for quality. Data should be tested on the staging environment. Data tier defines SLA for fixing bugs and data removal. For example, compliance - tier-1, temporary datasets - tier-5.
Previously, application developers implemented logging inconsistently. “Platformizing” logging introduced standard for logging, so developers didn’t have to concentrate on this topic anymore.
System Design
Zillow: Optimistic Concurrency with Write-Time Timestamps
ML Feature Serving Infrastructure at Lyft
Sharding, simplification, and Twitter’s ads serving platform
Third Time’s the Cache, No More
Software Architecture
Data Structures & Full-Text Search Indexing in Couchbase
Culture
Ten Mistakes to Avoid when Managing a Product Backlog
Products
Amazon S3 Glacier Price Reduction
Announcing Self-Service Production Clusters for HCP Consul
New Amazon EC2 X2gd Instances – Graviton2 Power for Memory-Intensive Workloads
Enhancing privacy-focused Web Analytics to better meet your metrics needs
A deep-dive into Cloudflare’s autonomous edge DDoS protection