
Highlights
GitHub: How we scaled the API with a sharded, replicated rate limiter in Redis
GitHub API has a limit on API calls per key. Such keys were stored in Memcached along with their reset_at value and number of calls. Memcached was also used for application caching purposes.
Such a solution works well but harder to scale. It was decided to have one Memcached per datacenter, in which case clients can face some issues if requests hit different datacenters. Also, because Memcached was shared with other application’s cache, it could sometimes “evict” rate limiter’s data.
As a solution, it was decided to use Redis. An application would pick a shard for the key. Primary would accept writes and replicas would accept reads. Redis has a native expiration feature, so no need for reset_at. Sounds good in theory but in practice there were bugs.
There was about 1 second discrepancy between X-RateLimit-Reset values in different responses. It happened because of a mixed logic for calculating this value between Lua (Redis) and Ruby (application). To mitigate the issue it was decided that only an application will calculate this expires_at value. They still used Redis native TTL feature but only to clean up old values from the database.
Another issue was that some requests were rejected although the response header said X-RateLimit-Remaining: 5000. It happened because primary doesn’t expire a key until it’s accessed, and replica doesn’t expire data until it receives an instruction from the primary. So reading a key from a replica and updating it on a primary caused this bug. As a solution, an application should be ready to receive stale data from Redis, in this case, ignore it.
Hotels.com: Bot Attacks: You are not alone
Hotels.com reviewed incidents for the past 12 months and identified bot attacks as one of the most dangerous threats. Besides DoS and DDoS, there is also data scraping. There are more sophisticated attacks that use brute force. The Hotels.com team has experienced an attack on the checkout page to find exploitable coupon codes, an attack on the Sign In page for an account takeover (ATO).
Basic attacks easy to block with a web application firewall (WAF), in this case by blocking the attacker’s IP address. More sophisticated attacks are distributed across different machines in various countries.
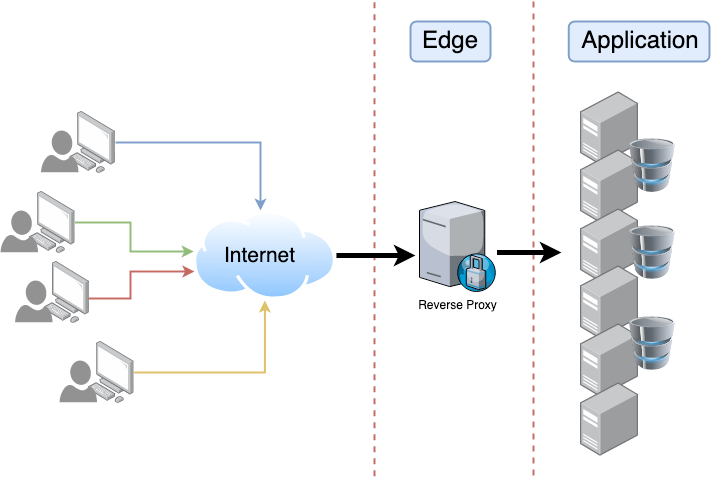
There are two levels of defense: edge level (reverse proxy) and application level. A trick to mitigate some attacks is to use the robots.txt file as a honeypot. Some bots deliberately try to access areas restricted by robots.txt. In this case, such bots can be identified and blocked.
Edge layer solutions have some interesting techniques, for example, serve alternative or cached response, delaying the request instead of blocking (tarpitting), deprioritizing bot requests over user requests. A disadvantage of the edge solution is that it involves a third party (Cloudflare, Akamai).
Common practices for application level mimic edge level: rate limiting, captcha. Be careful with authentication because it adds more complexity.
Bot attacks are expensive and require a lot of resources. Eventually, an attacker will exhaust their resources and stop the attack. It’s recommended to have alerts on autoscaling.
Discourse: Standing on the Shoulders of a Giant Elephant: Upgrading to PostgreSQL 13
The latest major update to PostgreSQL 13 brings B-tree deduplication and corresponding performance improvement on such indexes. The Discourse team decided to test the upgrade and see how it affects their case.
It was decided to use the largest table that Discourse has to test the update comparing to previous PostgreSQL 12. This table is about 1 billion rows, has several B-tree indexes, one of them with uniqueness constraint.
Tests showed that index size was reduced from 72 GB to 43 GB. Taking into account that the unique index didn’t change in size, the comparison on the rest of the indexes was about 21 GB against 7 GB.
How Facebook encodes your videos
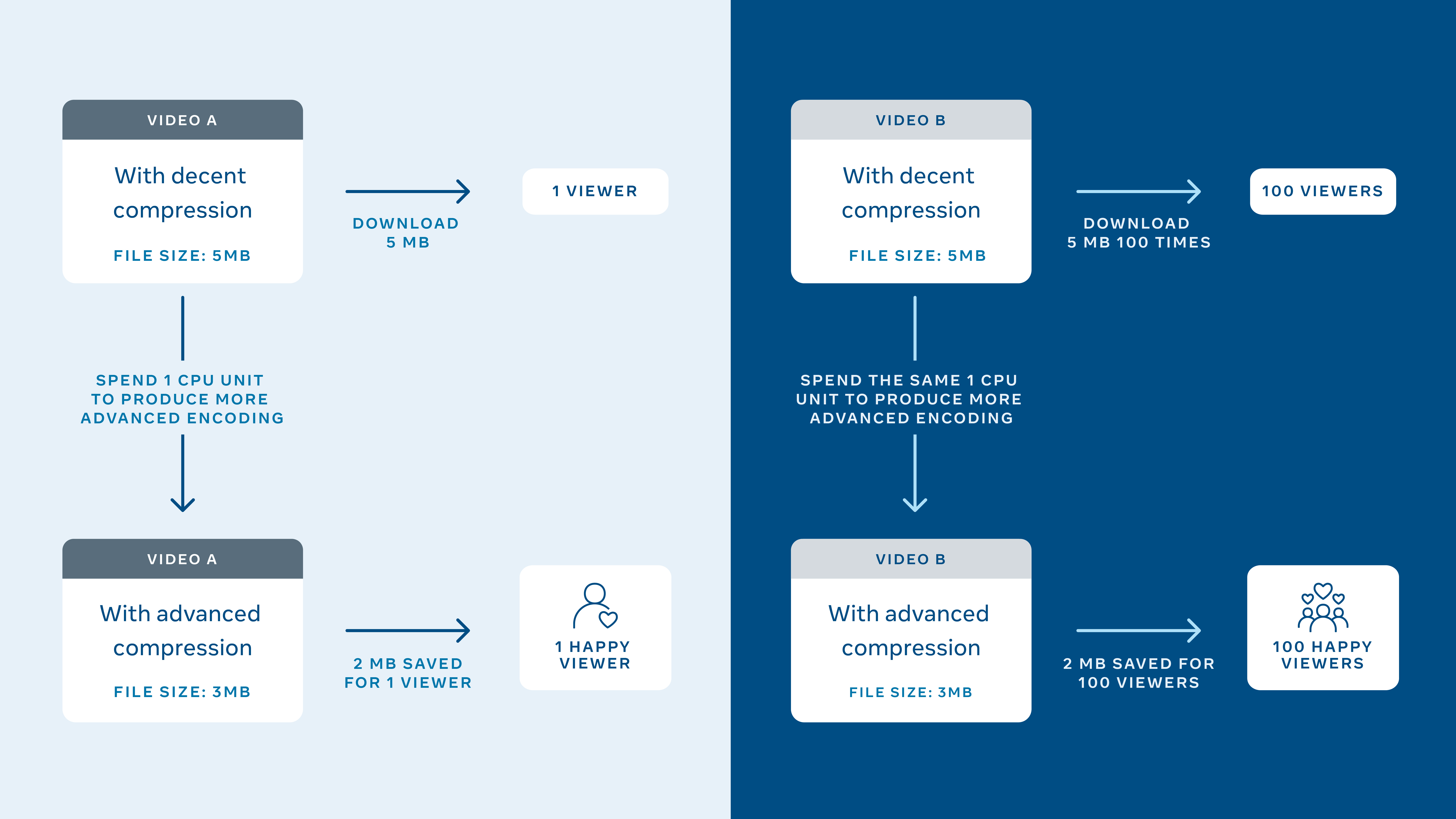
Millions of videos are uploaded to Facebook. Those videos should be encoded to different resolutions with different bitrate and different codecs. VP9 codec better compresses comparing to H264 but also consumes more CPU. Computational resources are limited. Some videos will be viewed more than others, some codecs are not supported on all devices. On each upload, Facebook adds the video to a priority queue.
Previously, priority was based on factors like the number of friends and followers, is it a licensed music video, is it a product video, etc. It didn’t take into account that any video can go viral. Also, it was hard to manage an ever-growing combination of codecs/quality/compression, etc.
The key to understanding the problem is an acknowledgment that a video consumes computational resources only once, no matter how many times it was later viewed. The Facebook team then came up with the formula that takes into account predicted watch time, cost of encoding, and compression efficiency.
The next step is predicting what videos will be viewed the most in the next hour. ML model is trained based on various parameters like the number of views of previous videos by the uploader, duration, type (Live, Stories, etc), and many more.
As a result, video views were less buffered, compression saved data on mobile, while improved video quality. Also, very compute-intensive encoding jobs were applied only to extremely popular videos.
AWS: Disaster Recovery (DR) Architecture, Part I: Strategies for Recovery in the Cloud
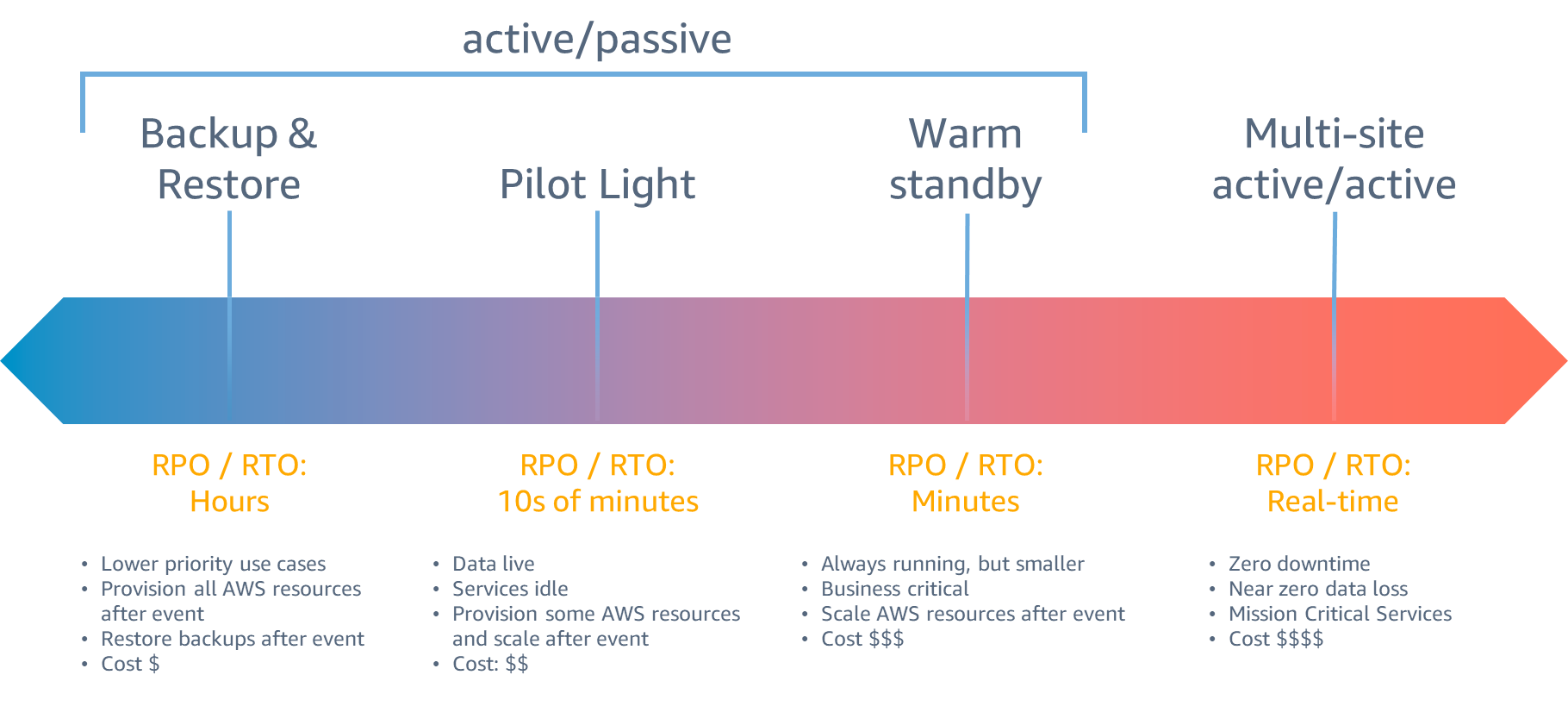
The main objectives for Disaster Recovery (DR) are recovery time (RTO), which represents a delay in a service interruption, and recovery point (RPO) which represents the amount of time since the latest recovery point. Better numbers cost more resources and complexity.
With active/passive strategy, the workload is served from a single (active) data center. In case of an incident, the passive data center takes over after a failover process. With active/active strategy, both regions are operational, data is being replicated. In case of a disaster event, all requests are routed to the remaining data center.
There is a need for backups even in case of active/active strategy to prevent other types of errors. Backup is created within the same region to S3 which is then copied to S3 in another region.
With the Pilot light strategy, passive infrastructure is shut off but ready to be up in case of an incident. Amazon Aurora Global can replicate between AWS regions. The warm standby strategy is similar but the secondary datacenter is up and running (sometimes with lower capacity) but it doesn’t service requests. Multi-site active/active strategy is similar to Warm standby but both datacenters serve requests. DynamoDB is a perfect tool for this strategy as data is being replicated within a second or so.
Product News
Announcing the release of Apache AGE 0.4.0 - PostgreSQL extension that provides graph database functionality
Announcing HashiCorp Waypoint 0.3 - Git repository polling and remote runners come to HashiCorp Waypoint to enable powerful workflows such as GitOps, along with more major improvements.
Dynamic URL Rewriting at the edge with Cloudflare
Update on git.php.net incident
System Design
Is Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL a better choice for me?
The Architecture Behind A One-Person Tech Startup
Tutorials
How to build a facial recognition system using Elasticsearch and Python