
Highlights
DoorDash: Optimizing OpenTelemetry’s Span Processor for High Throughput and Low CPU Costs
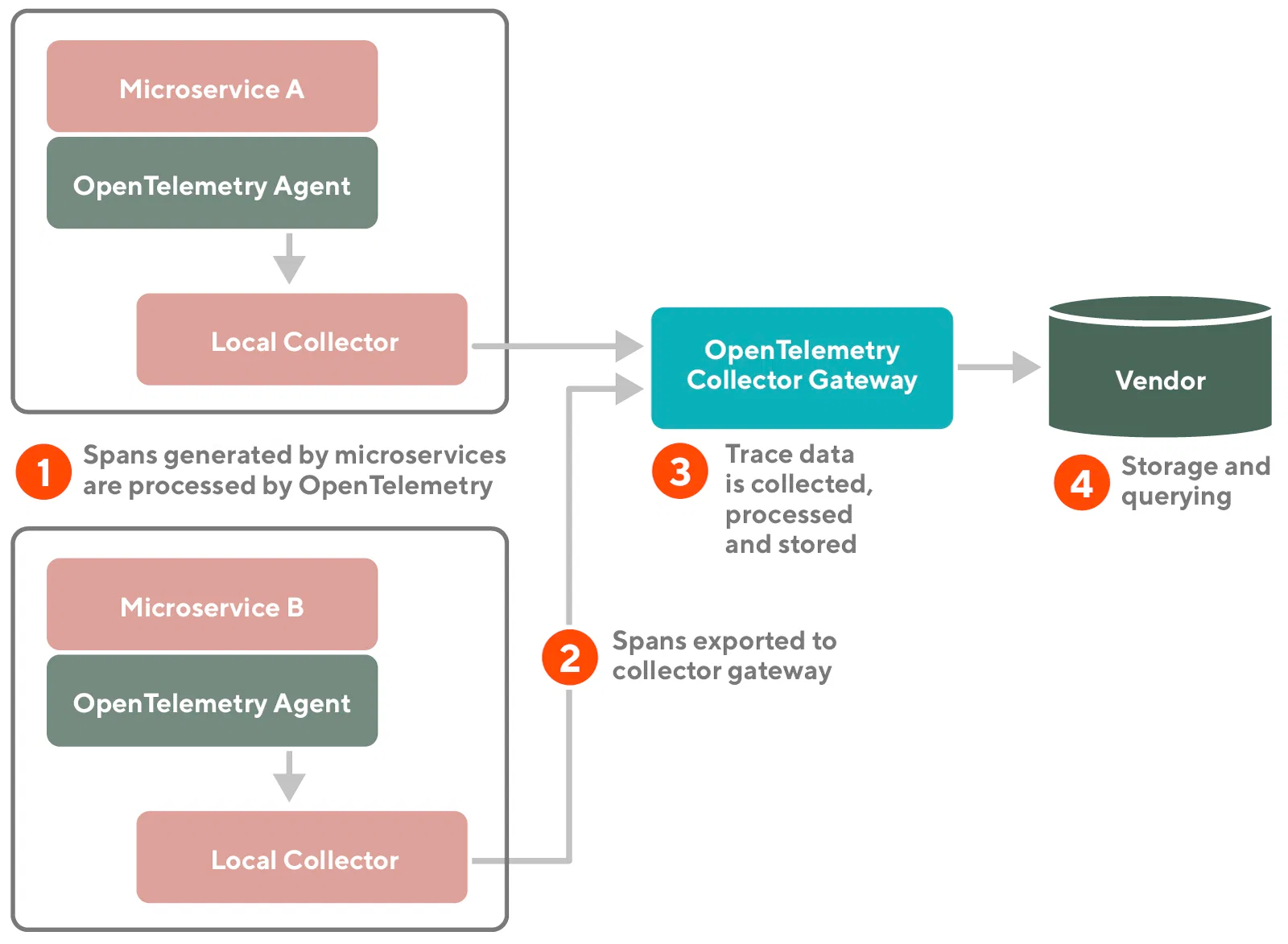
With an effort to migrate from the monolith to microservices, there is a need to trace requests between these services. OpenTelemetry is a new project aiming to become a standard. As a request hits a system, OpenTelemetry assigns a unique ID, all the underlying services (called spans) receive the same ID. Spans data is being collected on a local collector, then it’s sent to a collector gateway. Finally, tools like Jaeger, NewRelic, Splunk process and visualize this data. This a great way to profile and monitor distributed systems.
On the way to integrate with OpenTelemetry, the DoorDash team decided to run tests first to figure out the performance impact. This testing showed that CPU utilization went from 56% to 72% after enabling OpenTelemetry.
After profiling the application, the DoorDash team found the cause of the performance hit. It was constant polling of new spans from the queue. There are several different queue implementations in Java. It was decided to experiment and see if getting rid of the blocking queue in favor of another implementation would result in better performance.
After extensive testing, described in detail in the blog post, it was determined that the multi-producer single consumer queue (MpscQueue) worked the best. Final performance testing showed brilliant results - same 56% CPU utilization after enabling OpenTelemetry with the updated queue.
The DoorDash team made sure to commit the test results and required changes to the OpenTelemetry Java library.
Altoros: Performance Evaluation of NoSQL Databases as a Service: Couchbase Cloud, MongoDB Atlas, and Amazon DynamoDB
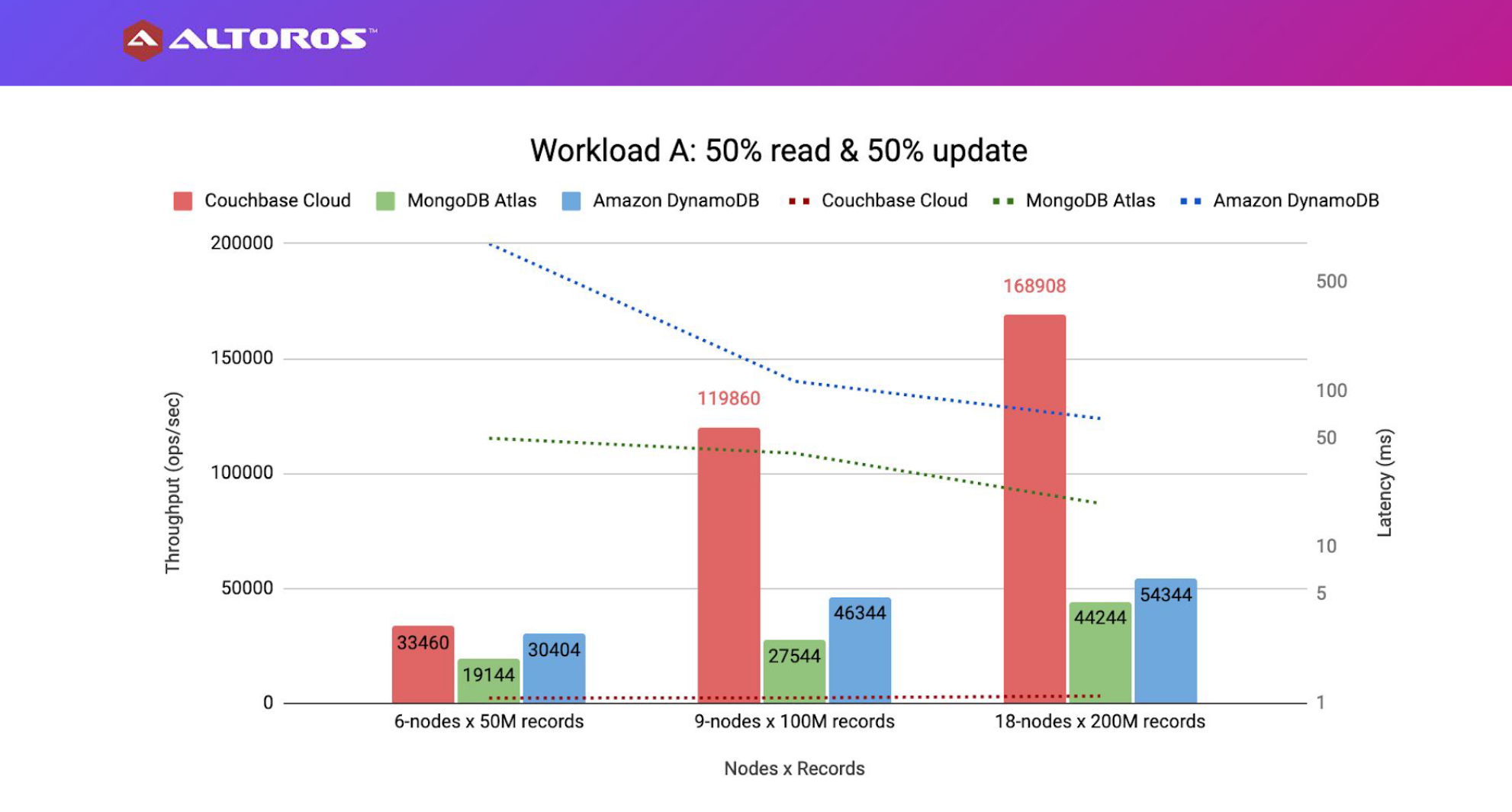
Altoros conducted a benchmark comparing DBaaS (database-as-a-service) of three NoSQL cloud solutions: AWS DynamoDB, MongoDB Atlas, and Couchbase Cloud. The 23-page report is available after the registration.
Benchmark explored three types of cluster configurations: 6,9, and 18 nodes. For that matter, a provisioned type of DynamoDB was used. The report also contains a pricing comparison. As DynamoDB is a serverless solution that scales automatically, they set limits to be on par price-wise with other databases.
Different types of queries were tested: 50/50 reads and writes, short-range scan, pagination with filtering, and JOIN query.
In conclusion, Couchbase Cloud beats competitors in most of the test cases, DynamoDB was not able to participate in JOIN and pagination cases due to its restrictions. MongoDB Atlas showed good results except for the JOIN test case.
CockroachDB: Living Without Atomic Clocks
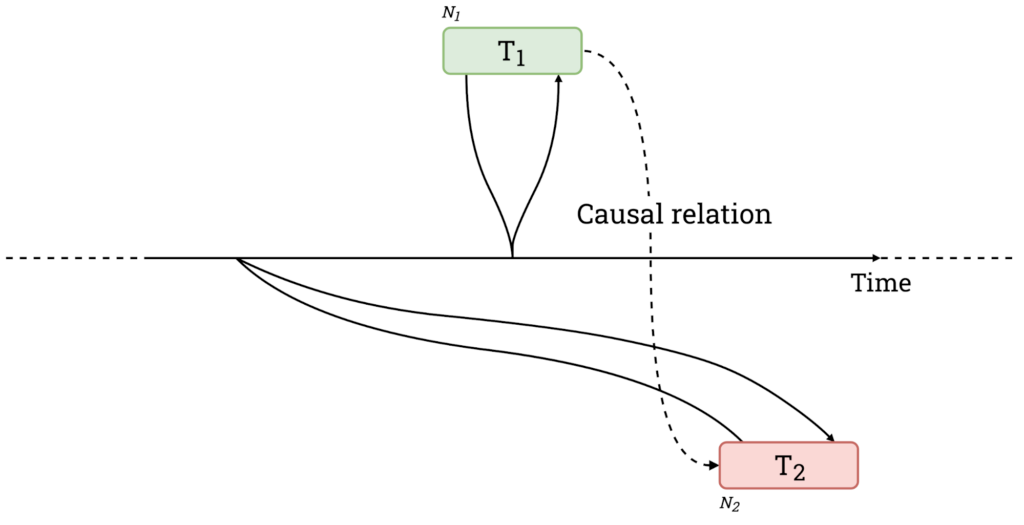
Clock synchronization is crucial for distributed systems. We can see it in causally related transactions in a distributed database. Transaction T2 should be committed after transaction T1. System time is different on different machines, so there is a chance that a commit timestamp for T1 is greater than the commit timestamp for T2. This violated the ordering of transactions.
Google Spanner and related whitepaper solve this problem with TrueTime. Google hardware time sync makes sure that instances are 7ms away max. Transaction wait 7ms to commit, in this case, subsequent transactions are guaranteed to commit after the previous one.
Another way to ensure linearizability is called “external consistency”, as the system relies on a single source of time for every operation. This is used internally at Google as Percolator.
Achieving similar results on-prem is challenging as there is usually no luxury of an atomic clock. NTP protocol difference can be between 100ms to 250ms. CockroachDB was inspired by Google Spanner, it uses a similar but different approach. Instead of waiting on write, it sometimes retries on read.
Each transaction defines a window of uncertainty as a range of current node timestamp and sum of current timestamp with cluster clock offset as an upper bound. If a transaction encounters value within the window of uncertainty, it simply bumps commit timestamp above the seen value but lower than the upper bound, effectively shrinking the window of uncertainty. In the worst case scenario, delay due to such uncertainty restart can be no more than clock offset, for NTP it’s 250ms. CockroachDB nodes periodically compare clocks between each other. If the maximum offset was exceeded for a certain node, it gets kicked out of the cluster.
Powering Messaging Enabledness with Yelp’s Data Infrastructure
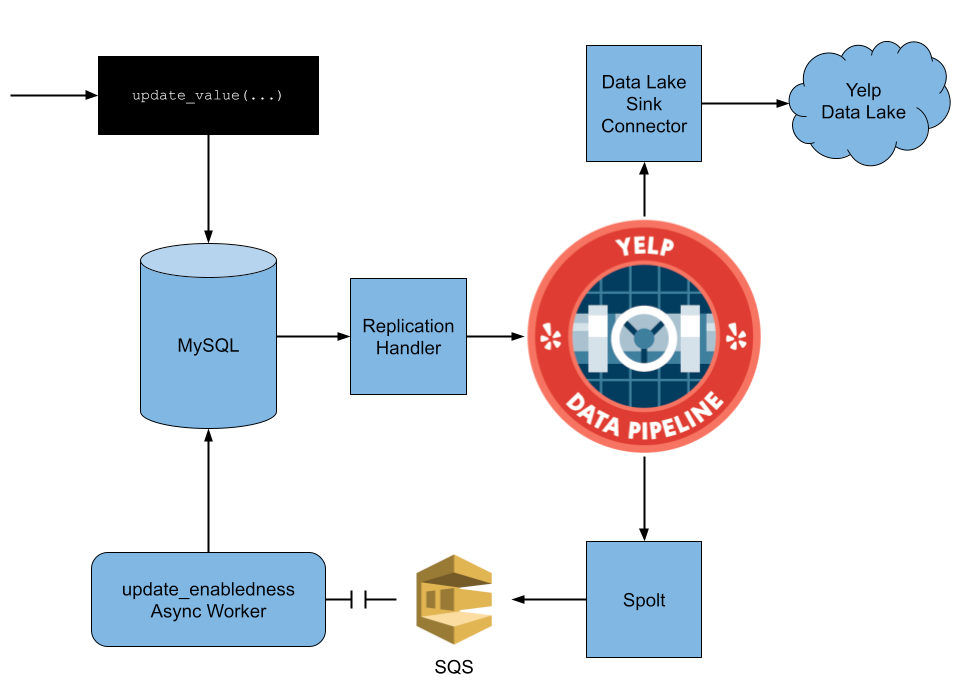
Yelp has a feature to message a business via the application. This feature is only available for businesses according to multiple criteria, for example, valid email. All these conditions can be queried by joining multiple SQL tables. Each change to those conditions should trigger a recalculation of the availability of this feature.
One way to solve this problem is to call this logic from within an application but in this case responsibility to maintaining correctness lays with an engineer, which can lead to human errors. Another solution is “change data capture”. Yelp developed (and open-sourced) CDC solution for MySQL. With CDC, any change to the data that may affect messaging feature is captured and processed to check the updated status of availability of this feature.
System Design
Reverse debugging at scale - Facebook developed a kernel probe to work with stack traces via Intel Processor Trace. In case of failure, it’s saved to a datastore, so an engineer can debug the code later. The also plan to develop a VS Code plugin for seamless experience.
Culture
A brief history of Rust at Facebook - Facebook started using Rust back in 2016 when they started writing Mercurial compatible version control system for their monorepo. Libra was also written in Rust. Currently there a more than 100 Rust engineers at Facebook.
What really happened at Basecamp
Basecamp implodes as employees flee company, including senior staff
Co-founders of Basecamp (one of them is the creator of Ruby on Rails framework) wrote several New York Times Bestselling books on corporate culture in tech. Despite being famous for its great culture, co-founders failed to prevent making fun of their customers by the support team for more than a decade. Finally, some of the employees started to speak up. In response, the company banned any political discussion at a workplace which received a backlash on Twitter. The company offered a generous severance package to leave the company to anyone that doesn’t agree with the new policy. More than a third of mostly senior staff left the company in the next couple of days.