
Highlights
Instacart: Don’t let the crows guide your routes
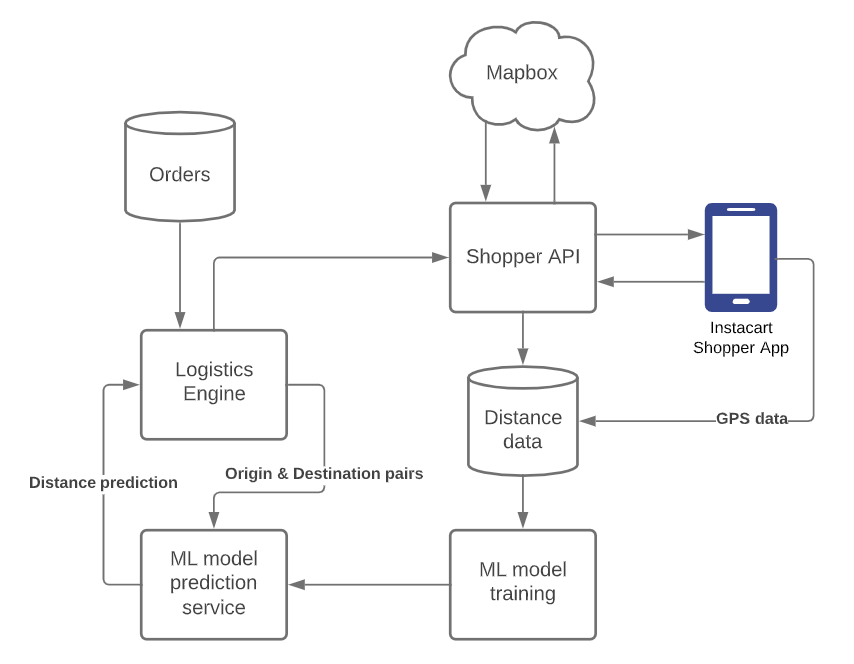
Instacart connects shoppers to make purchases and deliver them to the app customers. To make it more efficient, the application should calculate optimal routes to make purchases and deliver orders.
The easiest and the most naïve solution to calculate the path between two dots on a map is to calculate Haversine Distance - a straight line between two dots, similar to a bird flying between them. On average, the real distance by road is about 33% longer.
Using external services, like Mapbox, significantly increases distance accuracy computing. The mean error is only 5%. This comes with the price of calling third-party API with latency and price quirks. In addition, such a solution doesn’t scale to billions of trips even with caching previous results.
The remaining solution involves machine learning. Having historical trip data and cached Mapbox data, it is possible to build a model to predict the actual distance. The resulting error for such a solution is around 11%, which is not as good as Mapbox data but way better than Haversine distance.
There is a weekly job to retrain the model according to the new data coming in. The sample Python code is provided in the article.
DoorDash: Migrating From Python to Kotlin for Our Backend Services
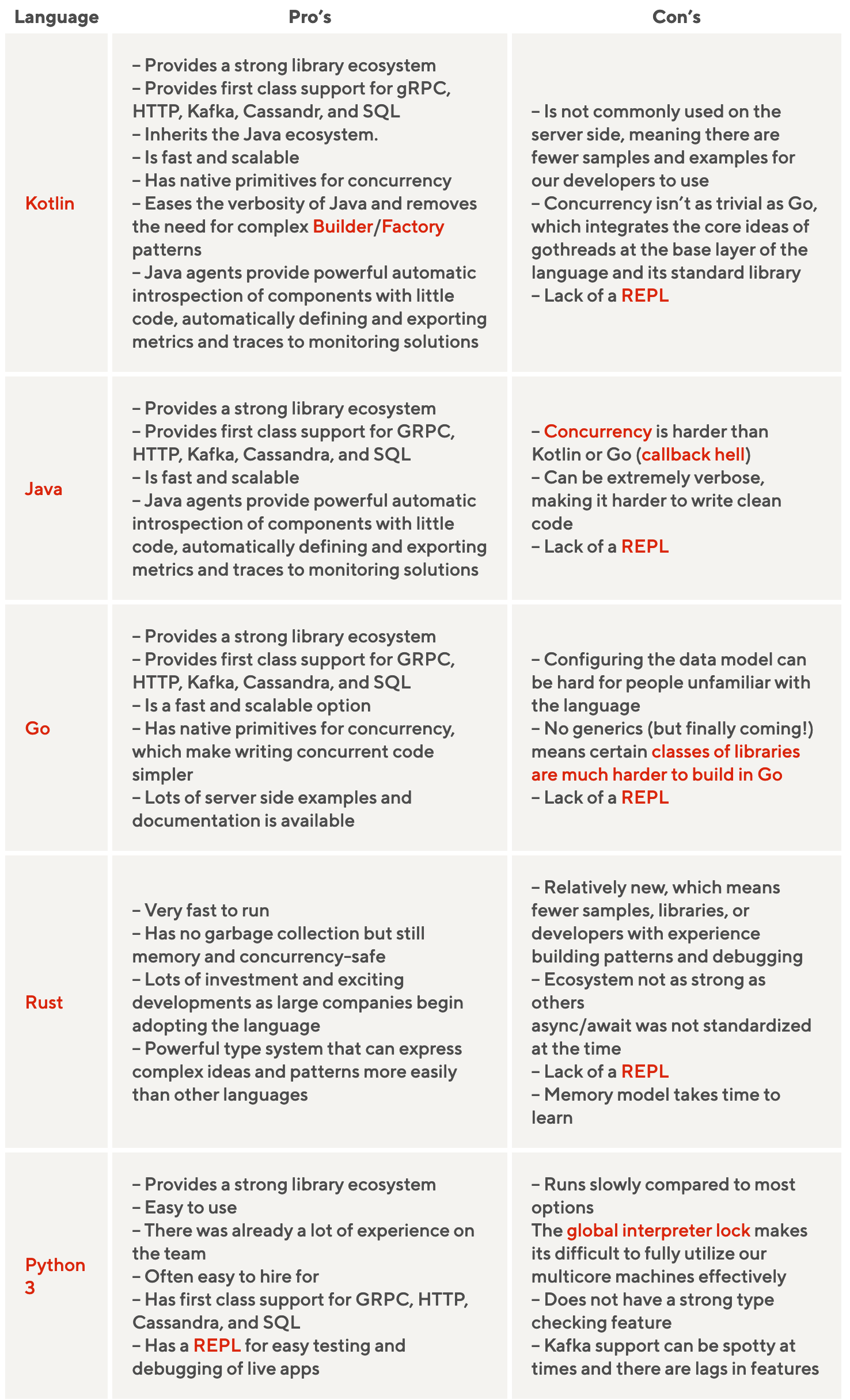
Legacy monolith application at DoorDash was Django app written in Python 2. As Python 2 reached the end of life, it was decided to use a single language for server software. This helps to share best practices across teams, build shared libraries, engineers to change teams with minimum effort. The team ruled out C++, Ruby, PHP, and Scala. The final language options were Kotlin, Java, Go, Rust, and Python 3. The pros and cons of each of these languages are described on the chart. The final decision was made in favor of Kotlin.
Here are some Kotlin benefits over Java:
- null safety
- better integration with Prometheus
- support of coroutines
It was challenging for the team to switch from Python to Kotlin, as most of the tutorials online aim for Android development. Senior staff at DoorDash wrote a Kotlin guide for their peers. Gradle dependency is challenging and less intuitive compared to other systems. DoorDash uses Artifactory to share libraries across projects. Some Java NIO libraries don’t scale well for coroutines, as they use a thread pool.
DoorDash team builds microservices with Armeria framework for microservices with gRPC for messages, Apache Kafka as a message queue, Apache Cassandra, and PostgreSQL as storage.
CNCF End User Technology Radar: Secret Management, February 2021
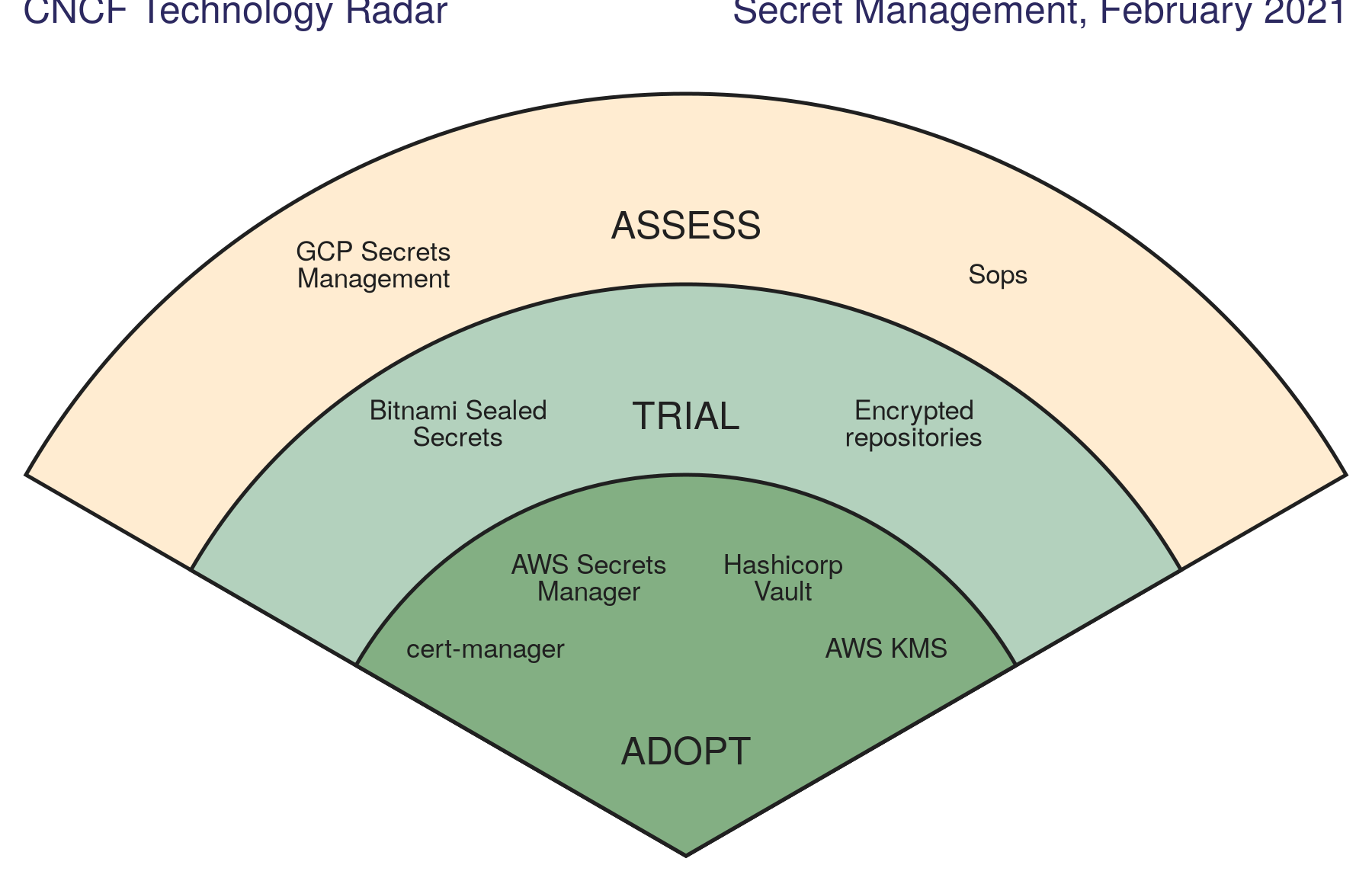
Cloud Native Computing Foundation released Secret Management Tech Radar with surprising results. It was expected to have cloud provider solutions getting wide adoption. While true for AWS KMS and AWS Secrets Manager, the most adopted technology turned out to be Hashicorp Vault. Its success can be explained by being a cloud-agnostic solution, which means there is no vendor lock with the cloud provider, also it’s a good fit for multi-cloud environments. With that being said, AWS, GCP, and Azure secret management systems are still popular options due to tight integration and automation that complements other cloud services. cert-manager seems to be the go-to solution for Kubernetes. It’s also worth mentioning SPIRE as a promising technology for service authentication.
Wallmart: Solr Performance Tuning
In this blog post, the Wallmart team shares their experience setting up Solr. Solr is a search engine written in Java and using Apache Lucene - the library that also powers Elasticsearch.
Initial Walmart set up was 40GB index over 5 shards with 8 core CPU and 28GB RAM, 16GB of which is allocated to JVM heap, leaving 12GB to index. With default settings, the application eventually crashed on performance testing showing overall terrible results, like 500s filter cache warmup, 100% CPU utilization, and 50s 99p latency.
Increasing hardware set up to 28GB RAM and 32 cores CPU improved the situation: 99p dropped to 111ms, 60% CPU, 70% JVM heap usage. This was a read-only test, so the next step was adding a 21K update per minute. This lead to 99p being around 37s while 95p remained around 100ms.
This is the part where an engineer gets to understand the underlying machinery of the system in use. Optimizing the query reduced p99 latency to 130ms. After this optimization, it was decided to run the test on the initial hardware setup, as it was one-third the cost of the upgraded one. Tests went well but degraded after 4 hours of testing.
Narrowing down the problem should find the bottleneck. Simplified queries without filters didn’t help. Querying only one shard to mitigate network effects of inter-shard communication didn’t help either. The next step is optimizing disk I/O.
Solr relies on Linux disk caching: most-used files are cached in memory. Reducing JVM heap size from 16GB to 8GB freed more cache memory. As a result, p99 latency is again within the expected 137ms while CPU and JVM heap are still under the limits.
The biggest lesson learned is to build a proper understanding of the underlying Solr design to evaluate and make the required optimizations.
Medium: Breaking up Big Fred
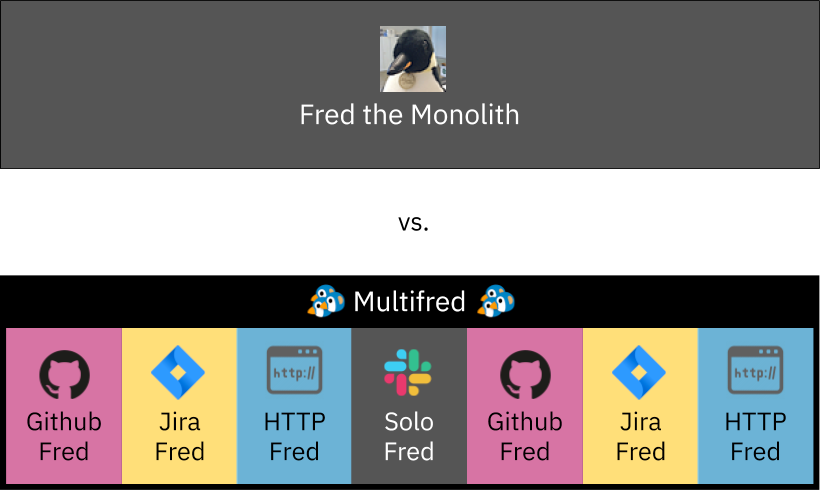
Fred is a Slack bot that is used internally at Medium. Fred has multiple features, like opening a helpdesk ticket, celebrating teammates, code review notifications for Github, JIRA comments, some cron jobs, and many more. Multiple teams contributed to monolith Fred but none had ownership over it.
One day Fred’s performance degraded to an extent that even restarts didn’t help. Log investigation didn’t show any useful results, Fred was dying quietly.
The Medium team made a simple decision - deploy several instances of the same monolith Fred service with different features “on”. For example, one instance handles Github, another handles JIRA, yet another handles cron jobs. The team never discovered the cause of the initial outage.
Tutorials
Capture changes from Amazon DocumentDB via AWS Lambda and publish them to Amazon MSK - AWS Change Data Capture solution for DocumentDB with Lambda and Kafka (AWS MSK).
Culture
My thoughts about the Principal role - how is a Principal Software Engineer different from a developer or Architect? Is it a management role? This blog post answers these and other questions about the Principal Software Engineering role.
Engineering Career Series: Using structured interviews to improve equity
“We focused on standardizing questions across all of our open roles to four key question types:
- Problem Solving
- System Design
- Ownership, Tenacity, and Curiosity
- Playing Well with Others.
Men were progressing to the next stage of the interview process at a higher rate than women. We were able to quickly reduce this gap by replacing individual interviewers’ judgment on a candidate’s performance with standardized pass/fail criteria. Interviewer bias still exists in your hiring process. We clarified what signals we wanted interviewers to look for and capture. Points are awarded for expected candidate behaviors. Interviewers are required to provide an explanation for when and why points are deducted.”