
Highlights
AWS: Diving Deep on S3 Consistency
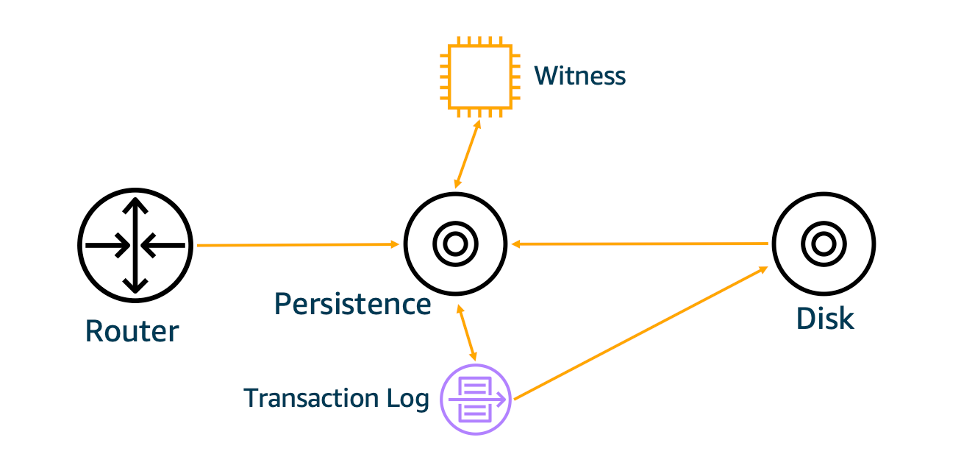
Werner Vogels, CTO at Amazon, shares the journey of building strong consistency for AWS S3. When S3 was launched 15 years ago in 2006, it was simple storage for files, backups, etc. The eventual consistency model was more than enough for such purposes. This means that sometimes API would return an older version of the object that was not yet propagated through the nodes.
Nowadays, however, S3 is also used as a data lake to run analytics, data storage to train machine learning models, etc. Such advanced cases require strong consistency as opposed to eventual consistency. There are several application-level solutions to ensure that S3 data is consistent. For example, Netflix came up with s3mper.
AWS team set a high bar for themselves: reach strong consistency for every S3 object with no performance and cost tradeoffs. In other words, have strong consistency by default free of charge with no performance implications.
Object metadata is persisted within the S3 subsystem with the cache in front of it. One way of achieving strong consistency would be getting rid of cache which is a huge performance hit. The solution comes from the CPU cache coherence protocol. So the actual solution to the problem is to keep the metadata cache strongly consistent.
The new replication logic keeps the order of operations for an object. The new Witness component observes any object mutation. It is now possible to check cache against the Witness to understand whether the cache is stale.
Witness only needs to keep track of a very small portion of data, hence it can keep everything in memory and respond fast.
Scaling up a Serverless Web Crawler and Search Engine
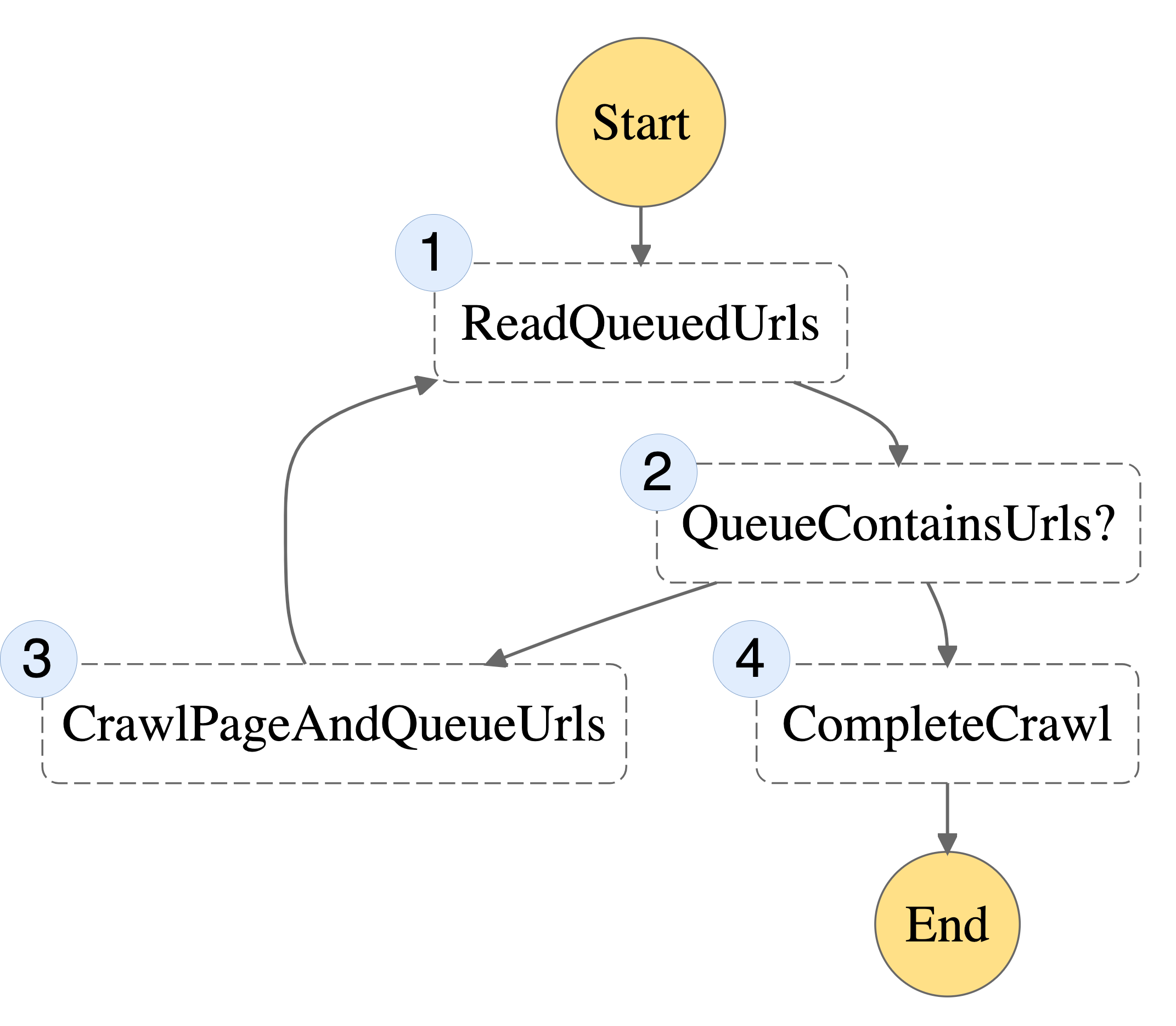
This tutorial explores the design pattern of decomposing and orchestrating AWS Lambda functions using web crawling as an example but it can be easily applied to other use cases. Lambda function execution is limited to 15 minutes. It is possible to overcome this limitation by adding a queue.
AWS Step Functions is the Lambda orchestrator that allows running serverless functions as a workflow. Step Functions has a limitation for I/O size, so instead of storing cache in memory, have a simple DynamoDB table. It can be created on workflow start-up and destroyed after the process is finished. Lambda functions interact with this queue.
With “Map State”, it is possible to run multiple functions in parallel. There is also maximum execution history size. In this case, spawn an additional Step Functions execution. There is native support for retries and error handling.
BBC: Rebuilding the moderation platform
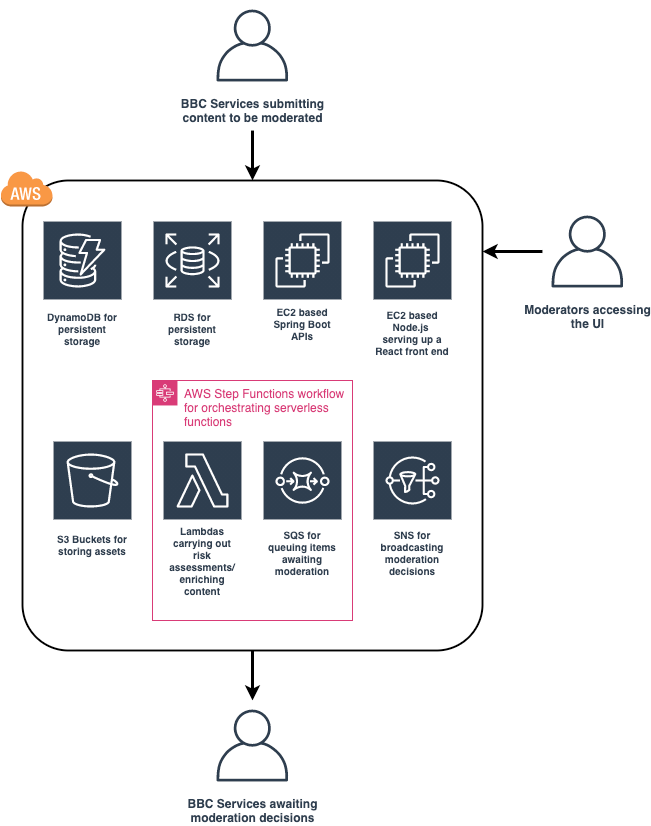
This blog post brings a higher-level overview of the moderation platform built by BBC. The platform is built in Java with Spring Boot framework for rapid API spin up. Moderators’ front end is developed in Node and React with future WebSockets integration. Infrastructure is built with AWS.
Risk assessors and content enrichers provide some supplementary information about submission, for example, highlight profanity. Service is orchestrated with AWS Step Function. It allows easy expansion of such modules as profanity detection, image moderation, audio transcription, text in picture detection.
Groupon: High Throughput with HTTP Connections
Groupon team experienced HttpHostConnectException error under a large load of traffic. Tests revealed that this error appears after 28K of open connections. This number represents the default value for ephemeral ports.
TCP connection opens a socket on both client and server. These sockets are then connected and create a socket pair, which consists of local IP and port, and remote IP and port. While the server port remains the same, the client port is selected randomly, hence the name ephemeral port.
After a connection is closed, it enters the TIME_WAIT state for 60 seconds for OS to ignore out-of-order packets. 28K port divided by 60 seconds gives us around 460 concurrent connections per second, which is not so much for a system under a significant load.
If an application’s average response time is 200ms, then 5 connections per thread, which is around 93 threads max. What if we can handle more than 93 threads? First, we can increase the max number of ports from 28K to 64K. Second, decrease TIME_WAIT from 60s to 15s. Finally, there is the Linux TCP option tcp_tw_reuse, which enables the kernel to reclaim TIME_WAIT slots and assign them to a new connection. Another solution is to make the application serve on two ports, in which case, we can double the number of available connections.
Airbnb’s Promotions and Communications Platform
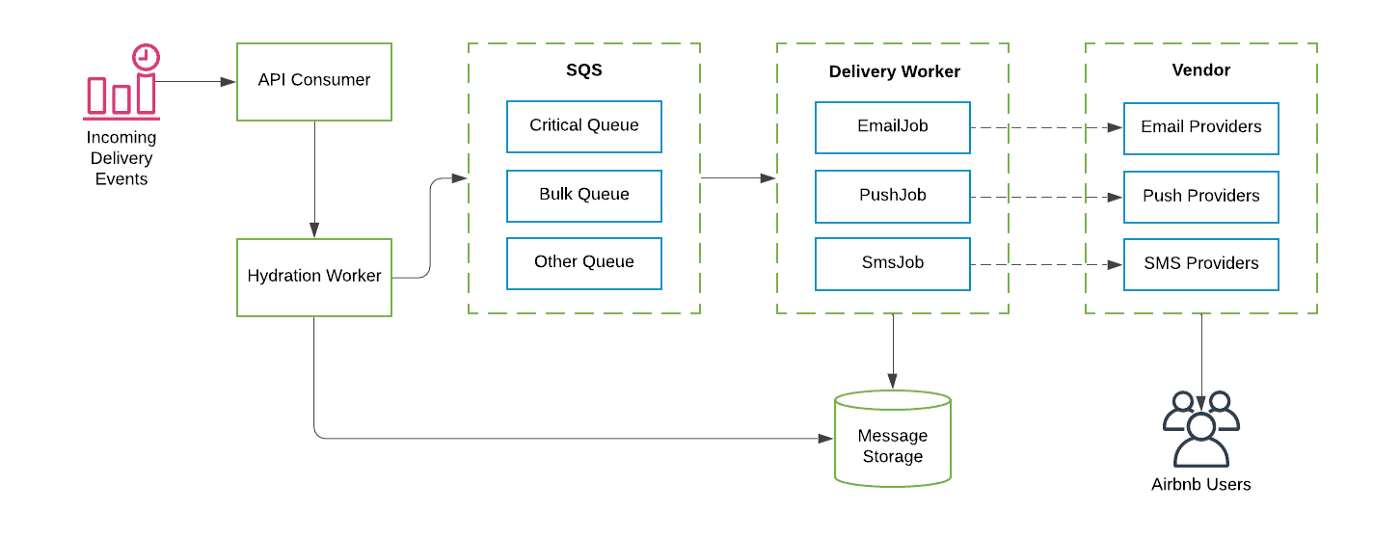
Airbnb team has developed an internal platform to manage and distribute content and messages to the users. It can be split into two major parts: transactional content and promotional content. Transactional content is related to user actions on the platform, like booking, messaging, etc. Promotional content communicates special offers, terms of service updates, and other promotions. The platform is called OMNI and is build with AWS.
The promotional part is a web app that supports a full cycle of content creation and distribution: management, building, approval, translation, analytics, versioning, templating, access control. Functionality is broken down into various services in the pipeline: audience service (get eligible users), workflow service (delivery orchestration), optimization service (messages personalization), presentation service (generates content), rendering service (email or push render), delivery service (sends out messages through various vendors, like SendGrid, Twilio).
The article reviews each service and provides a higher-level diagram. Audience service uses ElasticSearch to serve queries, internally build key-value storage, data is ingested with batch pipelines (Hive) and streaming jobs. Workflow service uses cron jobs and events, like new booking. Delivery service leverages AWS SQS to send email, SMS, and push notifications with less than 30 seconds of end-to-end delivery latency.
The system costs millions of dollars in vendor payments, SMS is the most expensive channel. Whatsapp and WeChat are also used in some locations.
System Design
How image search works at Dropbox - If you want to build an image search based on objects detection, this blog post gets an idea how it works.
AsyncAPI 2.0 - is a specification for event-driven architectures that was inspired by OpenAPI. It defines Producer, Consumer, Message, Channel, etc.
Product News
2021 State of Postgres Survey Results - 46% use AWS as a cloud provider, other 17% - GCP, 17% - DO, 15% - Azure. At the same time, 36% - self managed on site, while 30% use RDS. Majority of users refer to the database as Postgres (not PostgreSQL).
Kubernetes Adoption Accelerates but Operational Challenges Persist - according to the recent survey, more than 60% of Kubernetes users are running two or more clusters, while more than a half of all respondents are using multiple clouds.
Greykite library - an open source Python forecasting library developed by LinkedIn.
Orbit - another open sourced forecasting library, now it’s from Uber. Stands for Object-ORiented BayesIan Time Series
Tutorials
Best practices for monitoring dark launches - when running a dark launch, you deploy a new version of a service and route a copy of production traffic to it without returning responses to users.