
Highlights
Learn how Dream11, the World’s largest fantasy sports platform, scale their social network with Amazon Neptune and Amazon ElastiCache
Dream11 is a fantasy sports platform that has social network features. The team evaluated different graph database solutions for the social network service and chose Amazon Neptune after a load/stress PoC. Dream11 is already operating within AWS infrastructure so including a fully managed graph DB into the VPC was one of the factors. Also, Amazon Neptune came out as a performance winner.
Neptune uses Gremlin as the querying language for Labeled Property Graphs (LPG), which are powered by Apache TinkerPop, a standard graph computing framework.
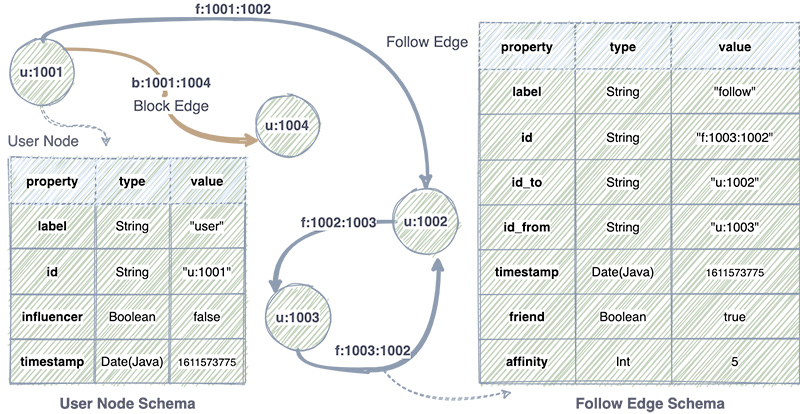
Graph DB schema is presented on the diagram below. Entities are divided into nodes and edges differentiated by labels. Edges describe the relationship between nodes using a label. For example, user “u:1003” follows user “u:1002”, user “u:1001” blocks user “u1004”. The edge would have an id “f:1003:1002” with the label “follow”. This helps to quickly answer the question of whether user 1003 follows user 1002.
The affinity property contains a value that represents the connection score. The higher the value, the stronger the relationship. This is determined by the Data Science team.
Neptune as a graph database is good for graph traversals, however, some operations, like list of followers and followings, and appropriate counts, can be optimized for performance because they should be computed every time. In addition, lists are expected to have pagination. To compute such paginated results, the database should traverse the graph from the very beginning, as there is no order like in a regular relational database. For example, if a user has 10 000 000 followers, then getting the paginated result of followers from 9 000 000 to 9 100 000 would make the database traverse the first 9 100 000 edges. Same for count operation. In general, such operations have the complexity of O(n).
To solve this problem it was decided to leverage sorted sets data type provided by Amazon ElastiCache for Redis. A set is a collection of unique items, while a sorted set is a collection of unique values ordered by some score. To represent a list of followers for a user, the keys for sorted sets of followers have the format followers_<user_id>, and the values are lists of tuples. A tuple consists of (<user_id, affinity_score>).
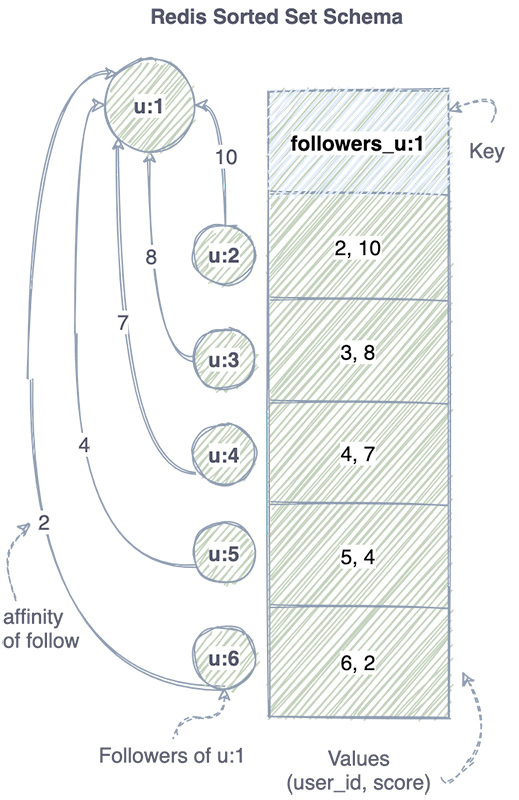
Pagination is implemented with ZRANGE operation which has the complexity of O(log(n)). The count is implemented with ZCARD operation with the complexity of O(1). This is a great performance improvement comparing to O(n) in a graph database. In addition, items are sorted by the affinity score associated with each follower.
Apache Kafka is used to keeping ElastiCache for the Redis cluster in sync with graph data in Neptune. Any change to Neptune is posted to Kafka. Kafka consumers read that message and update Redis. This is an asynchronous process. Redis cluster is deployed with Multi-AZ strategy with regular snapshots.
Stack. Application is written in Java with Vert.x framework and deployed to 100 EC2 instances behind Elastic Load Balancer. Neptune: one writer and five read replicas of size db.r5.12xlarge each. ElastiCache for Redis cluster of 10 shards, two replicas per shard of size cache.m5.12xlarge each.
The resulted throughput is 50 million requests per minute with 1.5 milliseconds latency. The solution can scale horizontally to support future growth.
The Service Mesh: What Every Software Engineer Needs to Know about the World’s Most Over-Hyped Technology
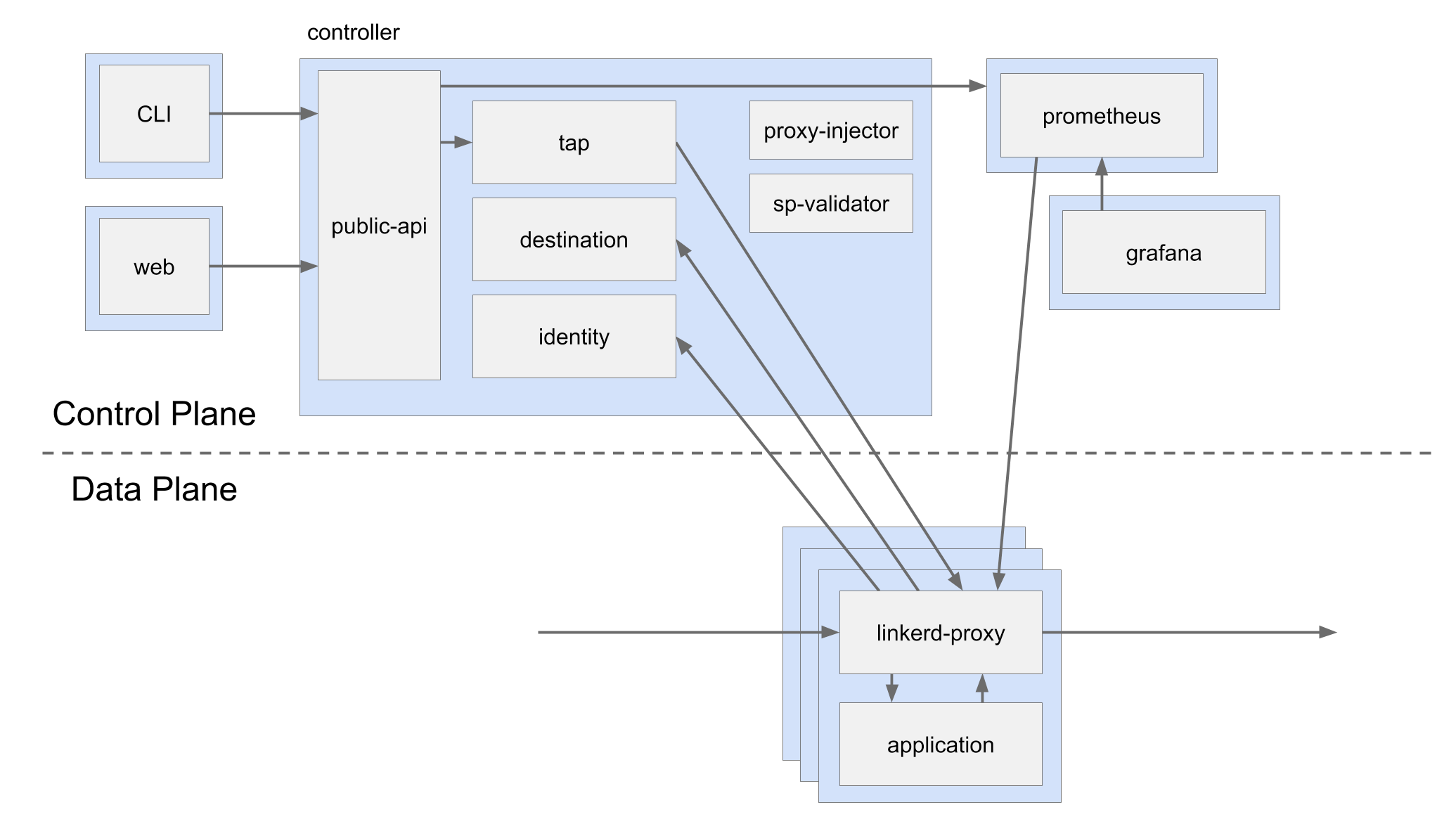
Service mesh represents a set of proxies attached to services and additional management processes. In service mesh methodology, proxies are called data plane, and management processes are called control plane.
Proxies are Layer 7 TCP proxies, just as NGINX or HAProxy. The most popular service mesh implementation Linkerd uses Linkerd-proxy. Other meshes use different proxies, for example, Envoy. In service mesh, proxies are used as both forward proxy (regular proxy) and reverse proxy. The main point is to use a proxy on the calls between different services.
The control plane coordinates the work of the data plane providing service discovery, metrics aggregation, TLS certificates, and more. The control plane is used to change data plane behavior.
The proxy is always run alongside application containers using a sidecar pattern. They should always be on the same pod in Kubernetes terminology.
Service mesh only makes sense for a system built with various services as opposed to monolith applications because it’s designed for service-to-service calls. Linkerd-proxy should always run with each instance of every service. Such architecture implies automatic deployment as it would be inconvenient to deploy this many proxies by hand.
Linkerd-proxy is written in Rust, which makes it fast, small and light. These qualities are essential as we add two proxy hops to every call - client-side and server-side.
The main goal of a service mesh is to make sure that the traffic between services is an ideal insertion point for functionality. It’s achieved by providing:
- Reliability features. Request retries, timeouts, canaries (traffic splitting/shifting), etc.
- Observability features. Aggregation of success rates, latencies, and request volumes for each service, or individual routes; drawing of service topology maps; etc.
- Security features. Mutual TLS, access control, etc.
L7 proxy operates on a request level. The client-side proxy can load balance a call to a server-side proxy across all the instances based on the observed latency. It can retry failed requests. The server-side proxy can reject a call if it’s not allowed or rate-limit it. Both sides can validate TLS certificates, hence mutual TLS. Linkerd doesn’t transform the request data, like payload, JSON body, or protobuf.
Service mesh is applied to every service regardless of its programming language or framework. It’s decoupled from the application, so every change in configuration, update, maintenance, etc. is purely platform level and requires no changes to the application. The main advantage that service development can focus on solving business problems and the platform takes care of the rest.
Facebook: Network hose - Managing uncertain network demand with model simplicity
How do we forecast the volume of traffic between two datacenters connected with a backbone network? There are very few companies in the world that face this problem, and yet it’s an interesting experience.
Building a backbone network can take months in case of terrestrial fiber or even years for submarine cables across the Atlantic Ocean. It’s unrealistic for service owners to provide a traffic estimate per datacenter pair. With current changes in traffic, it’s even harder to predict network consumption in a year. There is more, some datacenters are yet to be built. In addition, the network is a shared resource between different services. Tracking and investigating every traffic surge is increasingly difficult.
The Facebook team came up with a network-hose planning model. Instead of asking how much traffic a service would generate from X to Y, they ask how much ingress and egress traffic service is expected to generate from X.
The blog post gets into some mathematical details.
Deezer: Lifting our 2,000 favorite tracks limit
Deezer had a limitation of 2000 favorite tracks for the user. Increasing this limit was one of the most requested features.
Initially, Deezer app loaded all 2000 favorite tracks metadata on startup, which doesn’t make a lot of sense. Reducing the payload to only the needed information - trackID and date added, helped to decrease the initial payload by a factor of 30. This also improved app memory consumption, improved user experience with fast app startup.
Next, instead of loading all 2000 tracks at once, the application loads tracks metadata in batches of 500. Implementing such pagination reduced the pressure on servers.
Tutorials
A nice introduction that explains the key concepts of Kubernetes from the Bee Travels project - a demo project that builds an event-driven travel system based on microservices written in different languages.
Understanding Kafka Topic Partitions - a primer into Kafka’s key concepts.
Spring 2021 Distributed Systems course by Lindsey Kuper, CS professor at UC Santa Cruz. No distributed systems background necessary. Free!
Products
Cloud Run: A story of serverless containers - Cloud Run is a Google Cloud service similar to AWS Lambda or AWS Fargate. It runs containers instead of functions.
Learn Cloud Functions in a snap! - Function as a Service flavor from Google Cloud, a competitor of AWS Lambda.
Authorino - API protection solution that works with Envoy proxy and Kubernetes.