
I came across the word “exabyte” three times in just one today. Previously I didn’t even know this word exists. So 1 exabyte is 1,000 petabytes, or 1 exabyte is 1,000,000 terabytes. Companies operate at a scale of millions of terabytes now.
“Apple is apparently Google’s largest customer now, followed by ByteDance (parent company of the TikTok app). Apple holds 8 exabytes of data with Google Cloud, ByteDance is in the region of 500 petabytes — 16x less.”
“LinkedIn now stores 1 exabyte of total data across all Hadoop clusters.”
Facebook has built an entire distributed file system to store exabytes of data.
Google has helped create the most detailed map yet of the connections within the human brain. The brain map includes 50,000 cells forming 130 million connections called synapses, all rendered in three dimensions. The data set measures 1.4 petabytes, roughly 700 times the storage capacity of an average modern computer. “A whole mouse brain is only 1000 times bigger than this, an exabyte instead of a petabyte.”
Highlights
Robinhood’s: How we scaled brokerage system for greater reliability
Robinhood provides a brokerage system for individual traders. Two years ago the brokerage system received 100k requests per second at peak time. This number grew in just a half a year to about 750k requests per second.
The original brokerage trading system was built on a single database server with a dynamically scalable application server tier. Previously, a lot of team’s work was focused on vertical scalability, increasing the number of application servers, caching, optimizing slow queries, upgrading database sizes, or optimizing the application code.
However, at a certain point in time Robinhood team had to find a solution for the database scaling. They’ve reviewed Google’s Cloud Spanner, AWS’s DynamoDB, CitusDB, and CockroachDB but realized that migration to another DB engine from Postgres would require a significant amount of effort to rewrite not only the data access layer but business logic as well. So it was decided to build a sharding system on top of PostgreSQL with sharding the application to increase reliability through service isolation.
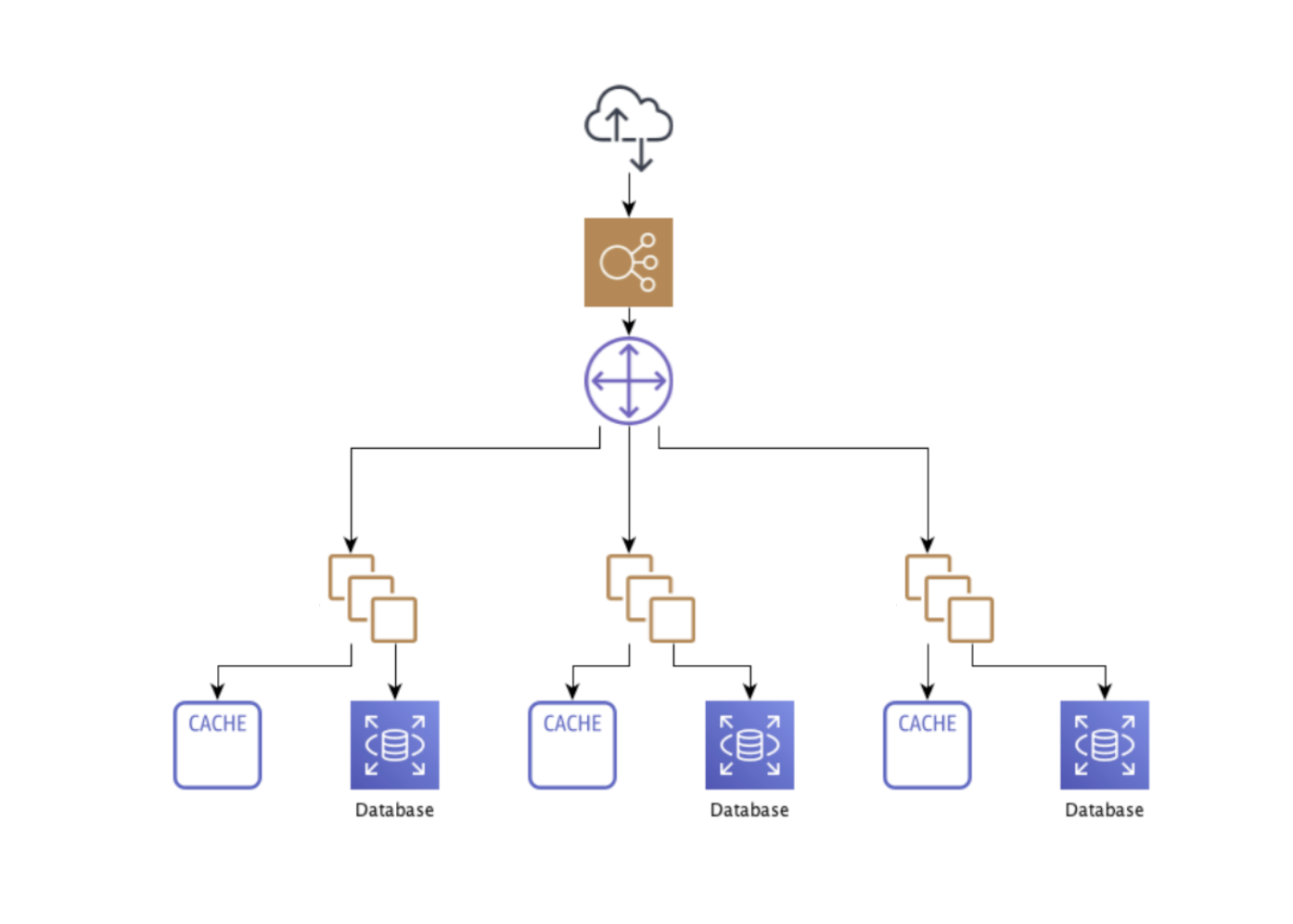
The design introduces sharding control layers to allow the newly divided system to appear as one. The routing layer is responsible for routing an external API request to the correct shard by inspecting and mapping the request to a user, which then maps to a specific shard. The aggregation layer allows other services to query data without knowing which shard it lives in.
The Kafka message streaming is set up for every shard to consume all messages, but only process messages that correspond to users that exist in that shard. For heavy cases, it’s possible to create specific topics for individual shards to avoid the overhead.
Building the aggregation layer was particularly challenging because the data that needs to be returned for any given request could now reside in multiple shards. The stateless aggregation service sends requests to all shards and aggregates the results.
The system started with only one shard at the beginning of 2020, now it’s 10 shards, each of which is capable to handle hundreds of thousands of requests per second.
Facebook: Tectonic Filesystem - Efficiency from Exascale
Before Tectonic, Facebook’s storage infrastructure consisted of a constellation of specialized storage systems. Haystack and f4 were used for blob storage. Data warehouse was spread across many HDFS instances.
Haystack was used for the frequently accessed content. Haystack’s effective replication factor was 5.3x. As data aged and got less frequent access, it was moved to f4, which is space-efficient with a replication factor of 2.8x but has lower throughput.
HDFS (Hadoop Distributed File System) was used for data analytics and AI training data and models. HDFS clusters are limited in size because they use a single machine to store and serve metadata. In some cases, a single data warehouse dataset exceeded a single HDFS cluster’s capacity.
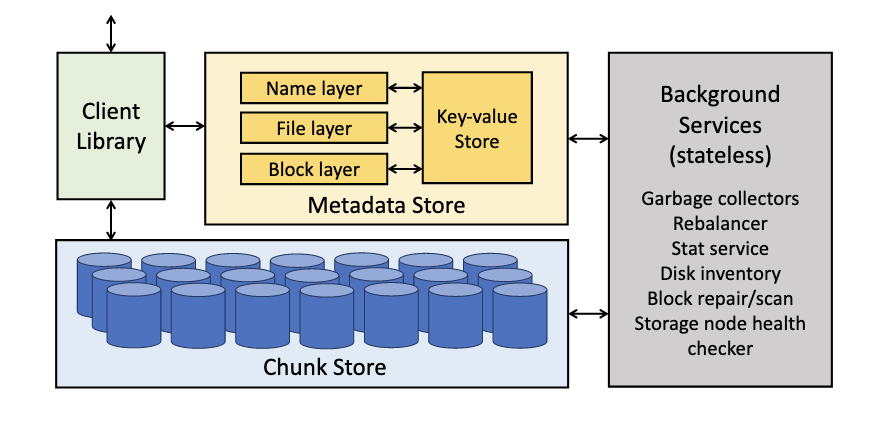
Enter Tectonic - Facebook’s distributed filesystem. Tectonic consists of storage nodes, metadata nodes, and stateless nodes for background operations. The Client Library orchestrates remote procedure calls to the meta-data and storage nodes.
Chunk Store is a cluster of storage nodes, each node has 36 hard drives and 1 SSD for metadata. Each chunk is a file on a local XFS. Blocks are composed of chunks. Tectonic provides per-block durability as multiple copies of the chunk are created. Background services repair damaged or lost chunks.
Metadata Store stores the filesystem hierarchy and the mapping of blocks to chunks. The naming, file, and block layers are logically separated with each layer hashed and partitioned separately. Metadata is stored in ZippyDB, a linearizable, fault-tolerant, sharded key-value store which in turn works on top of RocksDB. The name layer maps directories and subdirectories, the file layer maps files to a list of blocks, the block layer maps blocks to chunks.
The Client Library exposes a filesystem abstraction to applications. It reads and writes on the chunk level. The Client Library can write directly to storage nodes in parallel, allowing it to replicate chunks in parallel.
Facebook’s whitepaper goes into more detail on various optimizations, multitenancy management, running in production, trade-offs, and more.
HTTP/3 and QUIC: Past, Present, and Future
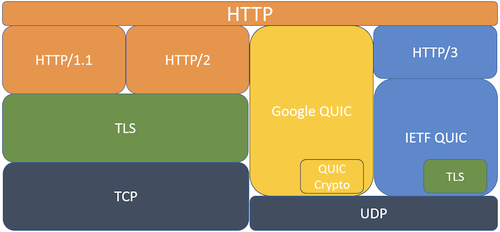
IETF QUIC RFCs have been published in May 2021. So what is all the fuss about? QUIC is a new transport for the internet. HTTP/3 is the mapping of HTTP which uses IETF QUIC as a transport.
Every device on the network can (and does) inspect TCP packets. QUIC improves privacy and offers substantially better performance in challenging network conditions.
It’s very difficult to deploy a protocol other than TCP or UDP on the internet. QUIC re-implements basic transport services within an encrypted envelope, using UDP to cross the internet.
The QUIC specification is described in several RFCs. The most important ones are RFC 9000 (QUIC: A UDP-Based Multiplexed and Secure Transport) and RFC 9001 (Using TLS to Secure QUIC). The former is version 1 of IETF QUIC, the core transport protocol. The latter describes the integration of TLS 1.3 and QUIC version 1. TLS is neither on top of nor below QUIC; the relationship is more complicated.
IETF version of the transport is stable and ready for production use. IETF working groups are already exploring QUIC as a transport for DNS, SSH, BGP, RTP, and many others.
System Design
A Deep Dive into Airbnb’s Server-Driven UI System - remember when Airbnb decided to get rid of React? Here is what they came up with.
The legacy WAF: 4 ways this antiquated technology fails to protect your apps - “PCI requirement 6.6 states that you have to either have a WAF in place or do a thorough code review on every change to the application. The legacy WAF is run in monitoring mode, where it watches traffic and logs any event as an attack. When it’s time for an audit, the legacy WAF gets flipped on for a short bit, then back off again. In reality, of course, some auditors don’t even care if you have it in active blocking mode. Just having a WAF in place is good enough for them.”
Multi-tenancy support for Android SDKs
Products
Stripe Extension for VS Code - generate sample code, view API request logs, forward events to your application.
New in Grafana 8.0: Streaming real-time events and data to dashboards
TiFS, a TiKV-Based Partition Tolerant, Strictly Consistent File System - PingCAP team came up with this file system written in Rust and based on the key-value store during their Hackathon.
Tutorials
Using GitHub Actions to deploy serverless applications - this example is for AWS SAM.
Database pointers - a collection of best practices for AWS RDS, MySQL, and more.