
Highlights
How WhatsApp enables multi-device capability
WhatsApp phone client was previously a source of truth. If someone wanted to use WhatsApp on another device, the messages would be transferred through the smartphone app. If the smartphone battery was drained, such a companion app would not be able to work. The smartphone kept the data.
WhatsApp now allows connecting 4 additional devices that are independent of the smartphone. Each device gets an identity key. Adding a new device will require biometric authentication if this feature is enabled by a user. The WhatsApp server maintains a mapping between each person’s account and all their device identities. When someone wants to send a message, they get their device list keys from the server.
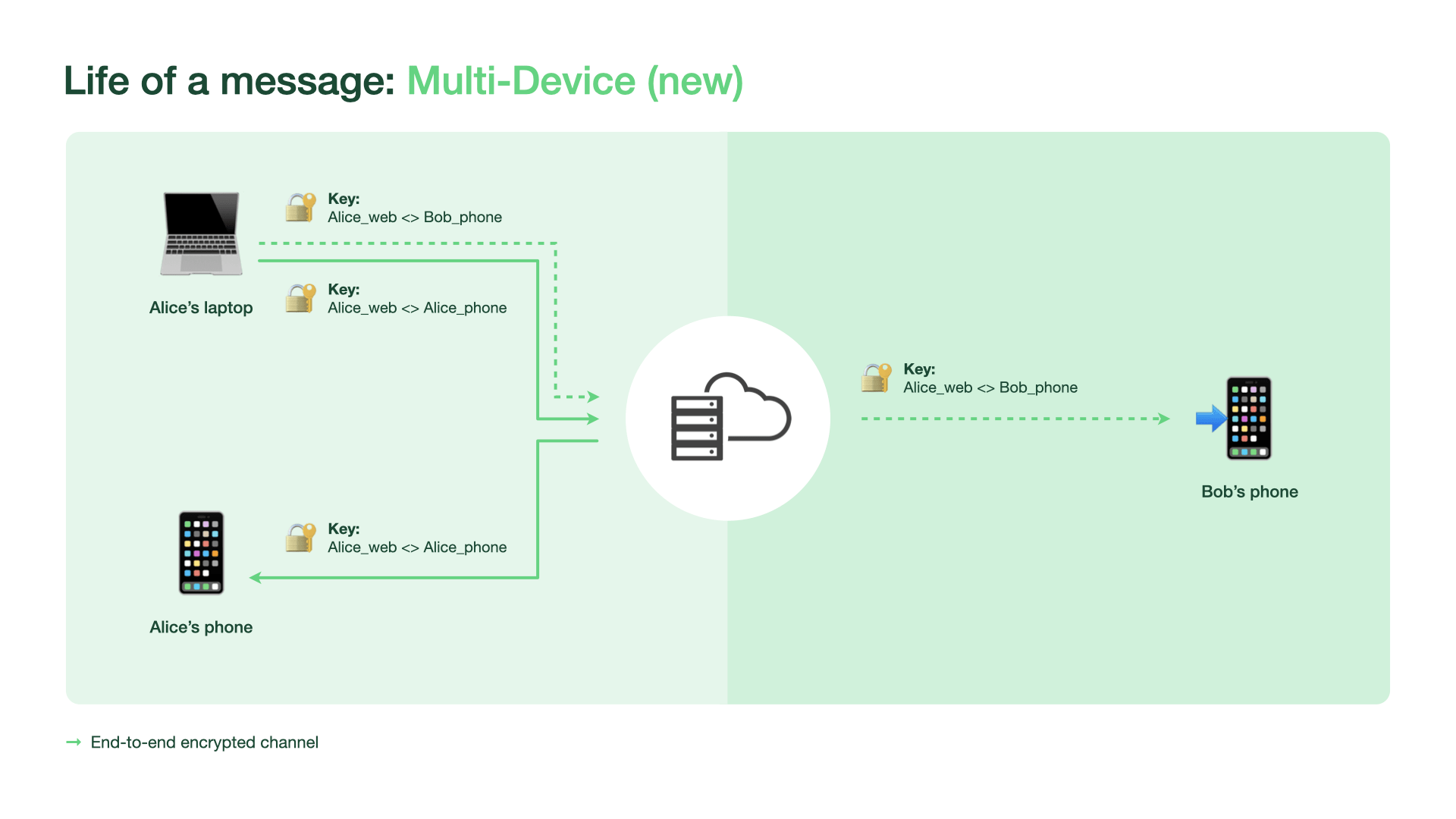
WhatsApp multi-device uses a client-fanout approach, where the WhatsApp client sending the message encrypts and transmits it N number of times to N number of different devices — those in the sender and receiver’s device lists. Each message is individually encrypted using the established pairwise encryption session with each device. Messages are not stored on the server after they are delivered.
For voice and video calls, the initiator generates a set of random 32-byte SRTP master secrets for each of the recipient’s devices. This secret is sent in a message to all the recipients’ devices. The call is protected by the SRTP master secret that was generated for a device that was used to answer the call.
For group calls, the server randomly selects a participant device that is in the call (either the initiator or a device on which a user has accepted the call) to generate the SRTP master secret.
For the initial device synchronization, the primary device encrypts a bundle of the messages from recent chats and transfers them to the newly linked device. The key to this encrypted message history is delivered to the newly linked device via an end-to-end encrypted message. After the companion device downloads, decrypts, unpacks, and stores the messages securely, the keys are deleted.
For ongoing synchronization, the WhatsApp server securely stores a copy of each application state that all of someone’s devices can access. All the information, and the metadata about the information, is end-to-end encrypted with constantly changing keys known only to that person’s devices.
How Wunderkind scales up to 200K requests per second using Google Cloud
Wunderkind is a performance marketing company that works with online retailers and publishers. After running into limitations with the legacy database system, they turned to Cloud Bigtable and Google Cloud. It helped to be more flexible and easily scale for high traffic demand which can be 40,000 requests per second.
Companies send events from their websites to Wunderkind. Black Friday and Cyber Monday get 31 billion events, sometimes as many as 200K events per second. Wunderkind shows 1.6 billion impressions that have seen close to 1 billion pageviews. Wunderkind also securely sends about 100 million emails. This scenario requires scalable solutions as well as the elasticity to pay only for what is used, and that’s where Google Cloud comes in.
Externally facing APIs, which are running on Google Kubernetes Engine, receive user events - up to hundreds of thousands per second. Those events go to Pub/Sub, Dataflow and from there they are written to Bigtable and BigQuery, Google Cloud’s serverless, and highly scalable data warehouse. Events can be things like product views or additions to shopping carts. The Bigtable key represents a combination of email address and the customer ID, and the event details are stored in that record.
The last time there was an event about a user is marked in Memorystore for Redis, Google Cloud’s fully managed Redis service. Another service periodically checks Memorystore for users that have not been active for a campaign-specific period. It then decides whether to reach out to them. In this case, Memorystore for Redis is used as a rate limiter or token bucket. Such requests are throttled with Memorystore in order not to overwhelm the email or texting providers API.
Product information is stored in Cloud SQL for MySQL. Memorystore for Redis is used to cache that information since many of the products are repeatedly called. Cloud SQL instance has 16 vCPUs, 60GBs of memory, and 0.5TB of disk space. Product information updates generate about a thousand write transactions per second.
Initially, the user history database was AWS DynamoDB. Wunderkind team had run into issues with hot shards with no way to determine how or why. The migration to Bigtable started with writing the data to two locations from Pub/Sub, performing some backfill of data until that was up and running. The migration lasted a few months until the full switch to Bigtable.
Bigtable instance that stores user events has about 30 TB with about 50 nodes.
Google Cloud: What you need to know about Confidential Computing
We are used to the best practices to keep the data encrypted at rest and in transit. Confidential computing allows keeping code and other data encrypted when it’s being processed in memory.
Confidential Computing is built on the newest generation of AMD CPU processors, which have a Secure Encrypted Virtualization extension that enables the hardware to generate encryption keys that are ephemeral and associated with a single VM. They are never stored anywhere else and are not extractable - the software will never have access to those keys. This creates a cryptographically isolated space.
Memory controllers use the keys to quickly decrypt cache lines when you need to execute an instruction and then immediately encrypts them again. In the CPU itself, data is decrypted but it remains encrypted in memory.
With Confidential Computing, you can encrypt data in use without making any code changes in the applications.
Confidential Computing Consortium includes vendors like Google, AMD, Red Hat, Intel, IBM, and Microsoft.
Tyrannical Data and Its Antidotes in the Microservices World
We start designing applications that cater to the database itself, possibly even implementing horrible elements like infinite stored procedures and awkward triggers. Many of the data breaches that you read about in the media are a result of storing sensitive data alongside non-sensitive data in the same database.
Concerning security and compliance, a microservices architecture allows you to split your sensitive and non-sensitive data between services. And all services should ideally perform information hiding, as defined by David Parnas, or only share what is necessary to accomplish their respective functions. Microservices can allow teams to function more independently from each other, allowing changes to be made and deployed without requiring high degrees of coordination between teams.
Apache Kafka gives you the chance to bring this data back together again. Simply add a reporting database to your ecosystem. You funnel your Kafka event stream into a relational database. Once the data is there, you can query it as usual. Push queries in ksqlDB resemble constantly updating SELECT statements written in SQL-like syntax.
Blogs and Articles
How We Built It: Snippets for Grammarly Business
4 Patterns for Microservices Architecture in Couchbase
Think gRPC, when you are architecting modern microservices! Benefits of gRPC: supports TLS by default, uses HTTP/2 which supports multiplexing of requests and responses, headers compression, binary data transfer. gRPC makes use of a language-agnostic data serialization mechanism called protocol buffers to specify the contract for remote procedure calls.
The Trouble with Service Mesh - The blog post is worth reading. Goes deep into network details. Long story short, TCP has a lot of overhead with all the layers of abstraction with containers, proxies adding even more overhead. The solution is UNIX sockets but the road is bumpy.
The 2021 Stack Overflow Developer Survey is here! - just in case you’ve missed it.
Tutorials
Implementing GitHub Enterprise OAuth2 With Passport.js
How to Replicate Your Data with DynamoDB Global Tables
Where should I run my stuff? Choosing a Google Cloud compute option
Create a Secure Chat Application with Socket.IO and React
Courses
Free training fundamentals courses from Elastic Enterprise Search
Amazon ElastiCache: In-memory datastore fundamentals, use cases and examples
Culture
How HashiCorp Does Developer Advocacy