
Highlights
Logging at Twitter: Updated
Centralized logging at Twitter was limited by low ingestion capacity and query capabilities which resulted in poor adoption. The previous solution ingested around 600K events per second per data center. However, only around 10% of the logs were submitted, with the remaining 90% discarded by the rate limiter. To address this, Twitter adopted Splunk Enterprise and migrated centralized logging to it. Now it ingests 4 times more logging data and has a better query engine and better user adoption.
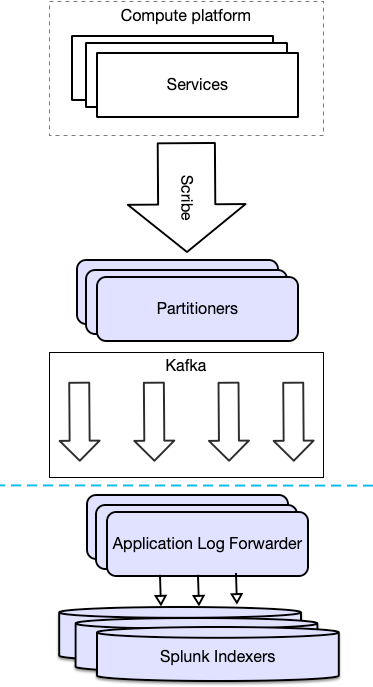
The Twitter team installed the Splunk Universal Forwarder on each server in the fleet. They’ve also created a new service to subscribe to the Kafka topic that was already in use for previous logging in-house solution (Loglens), and then forward those logs on to Splunk Enterprise.
The new service was named Application Log Forwarder (ALF). It reads events from Kafka and submits them to Splunk Enterprise using the HTTP Event Collector.
Currently, Twitter collects around 42 terabytes of data per data center each day. Going from log statement to on-disk storage takes less than 10 seconds. 5M events are ingested per second per data center.
Building well-architected serverless applications: Building in resiliency
AWS Lambda is fault-tolerant and designed to handle failures. If a service invokes a Lambda function and there is a service disruption, Lambda invokes the function in a different Availability Zone.
Partial failures can occur in non-atomic operations. PutRecords for Kinesis and BatchWriteItem for DynamoDB return a successful response if at least one record is ingested successfully. Always inspect the response when using such operations and programmatically deal with partial failures.
Long-running transactions can be processed by one or multiple components. Orchestrate such transactions using Step Functions with a saga pattern. Implementation of this pattern coordinates transactions between multiple microservices as part of a state machine. Each service that performs a transaction publishes an event to trigger the next transaction in the saga. This continues until the transaction chain is complete. If a transaction fails, saga orchestrates a series of compensating transactions that undo the changes that were made by the preceding transactions.
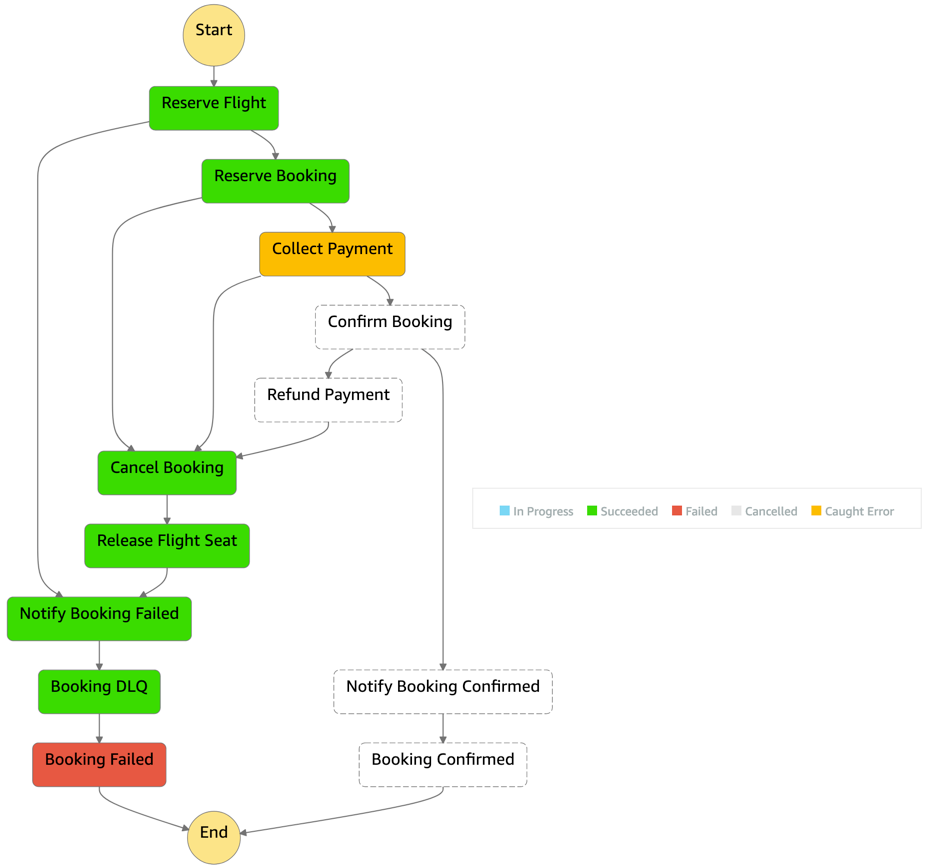
Within Step Functions, you can set separate retries, backoff rates, max attempts, intervals, and timeouts. Use the Step Functions service integration with SQS to send failed transactions to a DLQ (dead-letter queue) as the final step. Messages or events that can’t be processed correctly are stored in DLQ to a dedicated SQS queue. One you have resolved the issue, re-process the failed message.
Duplicate events can occur when a request is retried or multiple consumers process the same message from a queue or stream. A duplicate can also happen when a request is sent twice at different time intervals with the same parameters. Design your applications to process multiple identical requests to have the same effect as making a single request.
Idempotency refers to the capacity of an application or component to identify repeated events and prevent duplicated, inconsistent or lost data. This means that receiving the same event multiple times does not change the result beyond the first time the event was received. An idempotent application can, for example, handle multiple identical refund operations. The first refund operation is processed. Any further refund requests to the same customer with the same payment reference should not be processed again.
When using AWS Lambda, you can make your function idempotent. Create, or use an existing unique identifier at the beginning of a transaction to ensure idempotency. These identifiers are also known as idempotency tokens. Duplicate events might write to the same record with the same content instead of generating a duplicate entry. This may therefore not require additional safeguards.
DynamoDB Time to Live (TTL) allows you to define a per-item timestamp to determine when an item is no longer needed. This helps to limit the storage space used. You can also use DynamoDB conditional writes to ensure a write operation only succeeds if an item attribute meets one of the more expected conditions. For example, you can use this to fail a refund operation if a payment reference has already been refunded.
For example, Stripe allows you to add an Idempotency-Key: <key> header to the request. Stripe saves the resulting status code and body of the first request made for any given idempotency key. Subsequent requests with the same key return the same result.
Patterns: Microservice Chassis and Service Template
When you start the development of an application you often spend a significant amount of time writing the build logic and putting in place the mechanisms to handle cross-cutting concerns:
- Security - REST APIs must be secured by requiring an Access Token
- Externalized configuration - credentials, and network locations of external services such as databases and message brokers
- Logging
- Health check
- Metrics
- Distributed tracing - assigns each external request a unique identifier that is passed between services.
You will frequently create new services, each of which will only take days or weeks to develop. You cannot afford to spend a few days setting up every service.
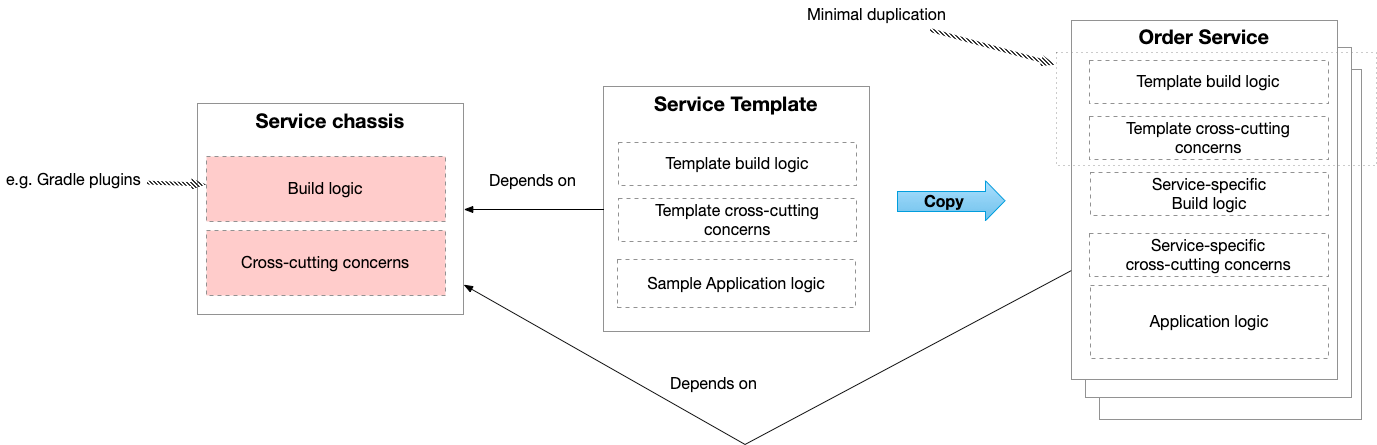
One solution is to create a Service Template, which is a source code template that a developer can copy to quickly start developing a new service. A template is a simple runnable service that implements the required build logic and cross-cutting concerns along with sample application logic. Beware, when the build logic and cross-cutting concerns logic needs to change, you must update existing services individually.
Create a microservice chassis framework that can be a foundation for developing your microservices. The chassis implements reusable build logic that builds and tests a service. You need a microservice chassis for each programming language/framework that you want to use.