
Highlights
HashiCorp State of Cloud Strategy Survey
HahiCorp surveyed 3200+ decision-makers from their contact database. Here are key takeaways:
- 76% of the companies are already multi-cloud. 86% plan to be multi-cloud in two years. 90% of large corporations adopt multi-cloud solutions while only 60% of startups moved towards this direction.
- Digital transformation is the main multi-cloud driver. Other reasons are avoiding single cloud vendor lock, cost reduction, and scaling.
- Service mesh adoption is expected to grow 2.5x — from 11% today to 28% in a year (with another 21% in the process).
- Skill shortage is the main challenge to multi-cloud operations.
- A third of respondents are spending more than $2 million a year on multi-cloud initiatives, and 6% are investing more than $50 million a year.
- 29% overspent their 2020 cloud budget, mostly due to shifting priorities or COVID-19.
- Companies mostly deploy open source solutions while around quarter use open source as a service.
Building well-architected serverless applications: Optimizing application performance
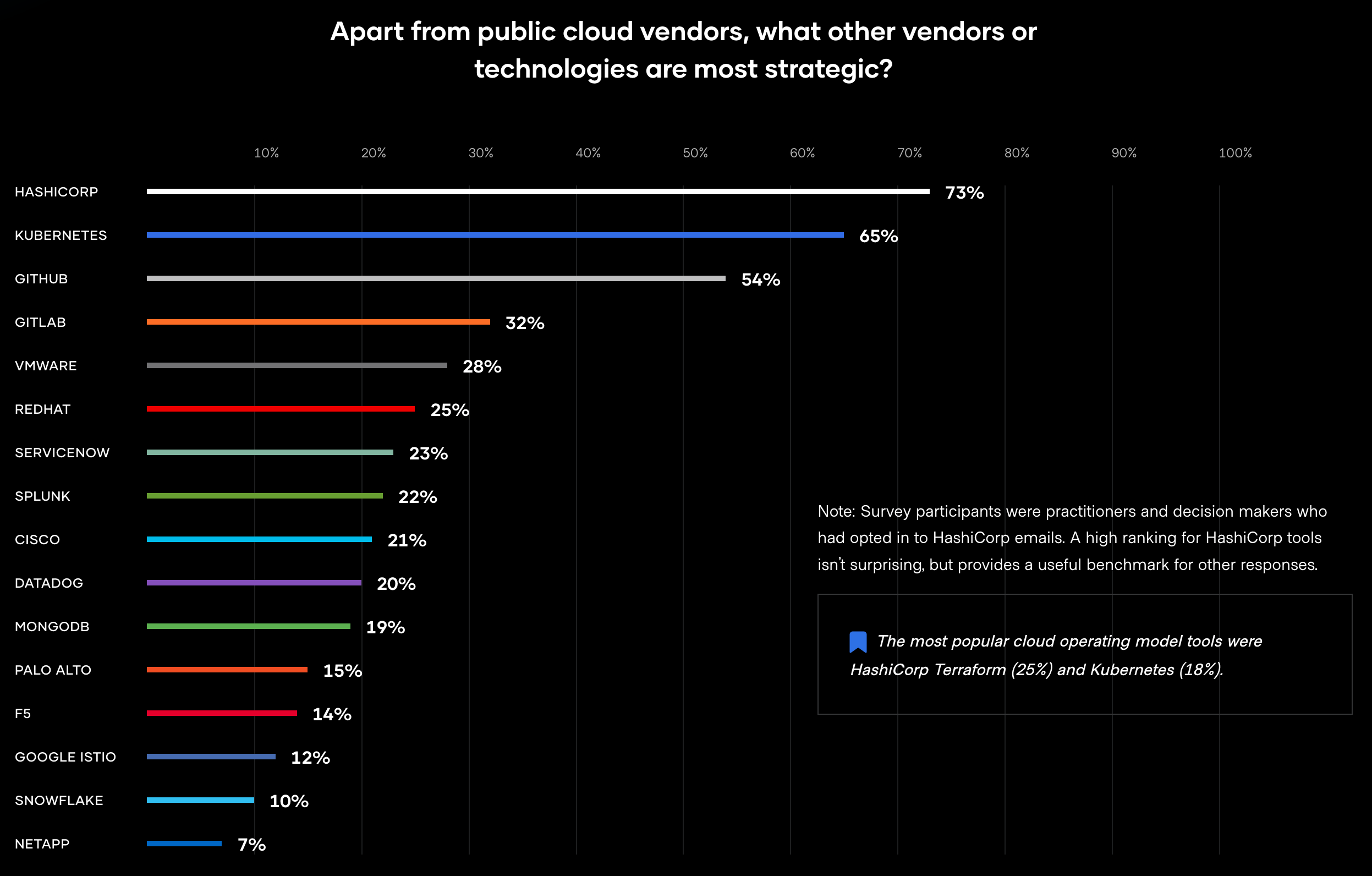
When a function is first invoked, the Lambda service creates an instance of the function to process the event. This is called a cold start. Lambda functions must contain a handler method in your code that processes events. During a cold start, Lambda runs the function initialization code, which is the code outside the handler, and then runs the handler code. During a warm start, Lambda runs the handler code.
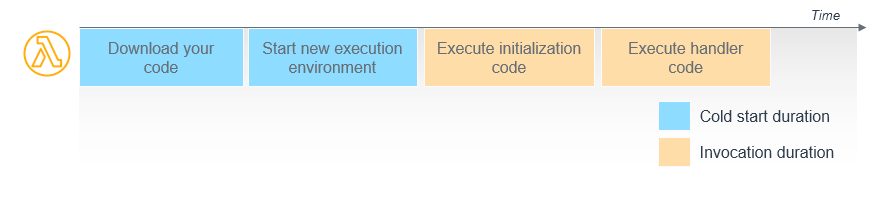
Initialize SDK clients, objects, and database connections outside of the function handler so that they are started during the cold start process. These connections then remain during subsequent warm starts, which improves function performance and cost.
Lambda provides a writable local file system available at /tmp. This is local to each function but shared between subsequent invocations within the same execution environment. You can download and cache assets locally in the /tmp folder during the cold start. This data is then available locally by all subsequent warm start invocations, improving performance.
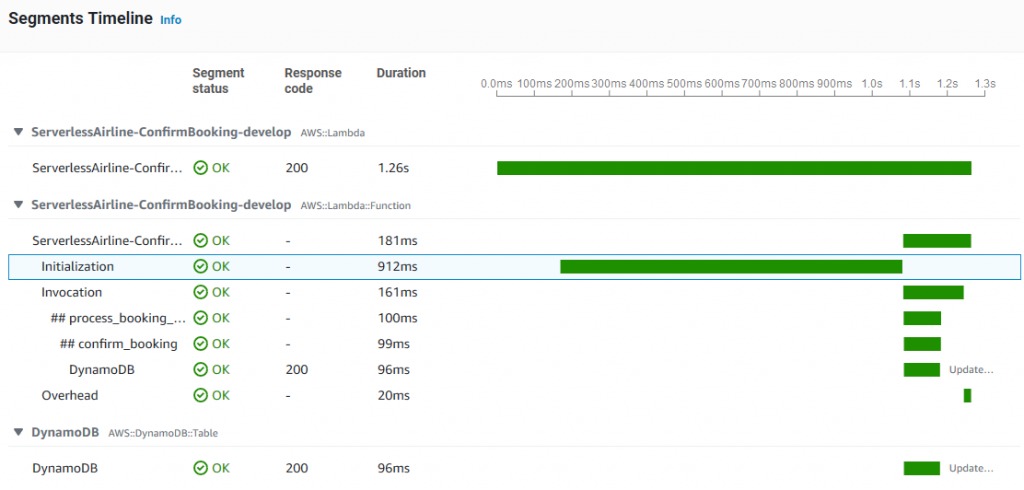
You can view the function cold start initialization time using Amazon CloudWatch Logs. A log REPORT line for a cold start includes the Init Duration value. This is the time the initialization code takes to run before the handler. When X-Ray tracing is enabled for a function, the trace includes the Initialization segment. A subsequent warm start REPORT line does not include the Init Duration value and is not present in the X-Ray trace.
AWS Lambda functions can be invoked synchronously and asynchronously. As synchronous processing involves a request-response pattern, the client caller also needs to wait for a response from a downstream service. If the downstream service then needs to call another service, you end up chaining calls that can impact service reliability, in addition to response times. The more services you integrate, the longer the response time, and you can no longer sustain complex workflows using synchronous transactions.
Favor asynchronous over synchronous request-response processing. With asynchronous processing, you pass the event to an internal Lambda queue for processing and Lambda handles the rest. An external process, separate from the function, manages polling and retries. Using this asynchronous approach can also make it easier to handle unpredictable traffic with significant volumes.
You can configure the amount of memory allocated to a Lambda function, between 128 MB and 10,240 MB. The amount of memory also determines the amount of virtual CPU available to a function. Adding more memory proportionally increases the amount of CPU, increasing the overall computational power available. If a function is CPU-, network- or memory-bound, then changing the memory setting can dramatically improve its performance.
AWS Lambda Power Tuning allows you to systematically test different memory size configurations and depending on your performance strategy – cost, performance, balanced – it identifies what is the most optimum memory size to use.
Amazon API Gateway edge-optimized APIs provide a fully managed Amazon CloudFront distribution. These are better for geographically distributed clients. API requests are routed to the nearest CloudFront Point of Presence (POP), which typically improves connection time.
Regional API endpoints are intended when clients are in the same Region. This helps you to reduce request latency and allows you to add your own content delivery network if necessary.
Products
What is Memorystore? - a fully managed in-memory data store service for Redis and Memcached at Google Cloud.
Your Google Cloud database options, explained - this picture says it all.
A New, Open Source Modern Apps Reference Architecture - NGINX came up with the “golden image” for modern apps architecture
Culture
How to be a successful manager of managers - Preeti Kaur, a VP of Engineering at Carta, shares her experience.
Tutorials
Game telemetry with Kafka Streams and Quarkus
Blogs
How we build Data Residency for Atlassian Cloud - more and more companies care about their data residency. Jira tickets and Confluence pages can now be stored in a specified realm per tenant. Atlassian Cloud relies on AWS.
Disclosure. I build Data Residency-as-a-service at InCountry in more than 90 countries.
Data Lineage at Slack - data lineage refers to the ability to trace how and where data sources are used.